Pytorch基础
本文最后更新于 2024年7月9日 晚上
新领域,新气象。
PyTorch入门
配置
在PyCharm中配置PyTorch时,需要使用本地解释器而非venv虚拟环境中的解释器,否则会出现torch.cuda.is_available()为False的情况。
常用操作
torch.reshape()
torch.reshape(input, shape):将输入Tensor变为形状为shape的Tensor
数据加载
Dataset
用于存储和管理数据的类。
torch.utils.data.Dataset是pytorch提供的抽象类。通过继承此类,可自定义另外的Dataset类。
通过重写__len()__和__getitem__()方法,可返回数据集的大小和每个数据样本及其Label。
Dataset类中一般必定存在一个成员变量,该变量是一个列表,存放数据的文件路径。
__getitem__()方法通常返回一个Tuple,元素0为数据内容,元素1为Label。
__getitem__()方法无需手动调用,在变量后加[idx]即可。类似于索引访问数组。通常,
__getitem__()方法根据idx从文件路径列表中取出对应的路径,进而根据路径获取数据本身。
通过运算符+,可以将两个Dataset作为一个列表的两个元素,构成一个2D的更大的Dataset。
Dataloader
用于从Dataset中为模型加载数据的类。
torch.utils.data.DataLoader提供了创建DataLoader对象的方法。
DataLoader(dataset, batch_size, shuffle, sampler, batch_sampler, num_workers, drop_last)
dataset: 数据集实例。
batch_size:批处理大小,默认为1.
shuffle:每次训练过后是否将数据集打乱。
sampler:
batch_sampler:
num_workers:进程数。
drop_last:数据集大小/batch_size除不尽时,余数是否丢弃。
DataLoader实例是一个迭代器,每个item都是一个2元素元组。
元素0是一个列表,包含了batch_size个数据。
元素1是一个列表,包含了batch_size个Label。
TensorBoard
SummaryWriter
from torch.utils.tensorboard import SummarWriter
SummaryWriter(str)实例化了一个存储在str文件夹中的 SummaryWriter对象。
SummaryWriter类用于在训练过程中向文件写入各类信息。这类信息可以被TensorBoard解析并以可视化的方式呈现。
add_scalar()
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None)
tag是对数据的标识符。
scalar_value是要添加的数据。
global_step是当前训练的步数。
add_image()
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats=‘CHW’)
tag是对图片数据的标识符。
img_tensor是图片数据。可以为Tensor、ndarray或string。使用
np.array(PIL.JpegImageFile)即可将PIL图片转换为ndarray。此种方式转换的ndarray的shape为(H, W, C),即三个维度分别对应高度、宽度和通道。
因此,此时add_image的dataformats参数应当为‘HWC’。
也可用torchvision.transforms.ToTensor()将PIL图片转化为Tensor。
也可用cv.imread将PIL图片转化为CHW的ndarray。
add_graph()
add_graph(model, input_to_model=None, verbose=False)
Transforms
from torchvision import transforms
transforms用于对图片数据进行变换。该模块内置了若干工具类,
Compose()
Compose(list of transforms object)用于组合多个transforms对象。
1 | |
ToTensor()
ToTensor()用于将对象转换为Tensor对象。
1 | |
ToPILImage()
将ndarray或Tensor对象转换为PILImage。
Normalize()
使用z-score法将Tensor对象标准化。
transforms.Normalize(mean=list, std=list)
对于mean和std,图片有几个通道,它们就是有几个元素的list。
list各元素的值需要对数据集中的每个元素的每个通道计算得出。
输出:(原始值-均值)/标准差
作用:将图像的数据分布转换为标准正态分布。
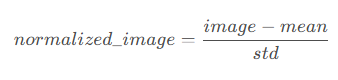
Resize()
将给定的PILImage变换至指定尺寸。
transforms.Resize(size)实例化了一个Resize操作对象。
当size为2元素列表时,第一个元素是高,第二个元素是宽。
当size为int时,图片更小的边将被缩放至int。
transforms.Resize(img)用于将已实例化的缩放操作应用于PILImage。接收的参数可为PILImage,也可为Tensor。
RandomCrop()
根据给定的size随机裁剪原图片。
transforms.RandomCrop(size)实例化了一个RandomCrop对象。
可选参数:padding:int,2元素列表或4元素列表。分别对应:
- 在图片四周添加int像素的间隔。
- 在图片左右添加[0]像素间隔,上下添加[1]像素间隔。
- 在图片上下左右分别添加[0]、[1]、[2]、[3]像素间隔。
pad_if_needed:布尔值,当裁剪大小大于图片大小时,自动添加padding。
fill:int或3元素列表,用于填充padding的像素色。分别对应:RGB(int, int, int)和RGB(r, g, b)
transforms.RandomCrop(img)用于执行裁剪操作。
torchvision数据集
以CIFAR10数据集为例。
1 | |
除上述属性外,还有:
transform属性:可传入transforms函数,对数据进行预处理。
神经网络
nn.Module
nn.Module是所有神经网络的基类。
自定义一个神经网络类,首先要做的便是继承nn.Module,随后实现__init__()和forward()函数。
实现__init__()函数时,首先要调用super().__init__()。其中classname为自定义类的类名。
forward()函数实现了前向传播。它接收一个x参数输入,对x进行一系列处理之后返回。
2
3
4
5
6
7
8
9
10
11
12
13import torch
from torch import nn
class MyNetwork(nn.Module):
def __init__(self):
super(MyNetwork, self).__init__()
# 将各层操作作为变量存储
self.layerfunction1 = nn.Conv2d(...)
...
def forward(self, x):
output = self.xxxfunction(x)
return output
nn.Sequential
Sequential用于保存一系列层操作,如卷积、非线性激活、池化等。类似于Transforms的Compose。
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLu)
输入x可省略。
卷积
卷积(Convolution)是让两个函数经过变换得到第三个函数的过程。
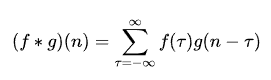
torch.nn.function模块中,提供了从1D到3D数据的卷积函数:conv1d()、conv2d和conv3d。
以conv2d()为例:
conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) -> Tensor
input为输入的Tensor。在CV中,这个Tensor一般是2DTensor,是Image经过ToTensor()变换的结果。对于input的Tensor,其形状必须满足
(minibatch, in_channels, iH, iW)
minibatch是DataLoader的batch_size。
in_channels是图片的通道数。
iH、iW分别是图片的高和宽。
weight权重,又叫卷积核。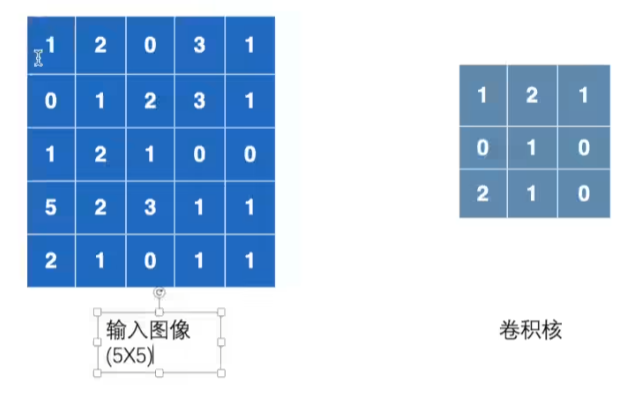
卷积核就像一个遮罩,对输入图像的局部进行处理。卷积核上元素值的不同,卷积结果就不同。元素值就是一个个权重。
权重的形状必须满足
(out_channels, in_channels/groups, kH, kW)
out_channels是输出图片的通道数。
bias偏置。
stride步进。直观来讲,步进是卷积核在输入图像上方每次移动的像素数。步进既可以是一个数,也可以是元组(sH, sW)。前者是横向移动的元素数,后者是纵向移动的元素数。
padding间隔。直观来讲,对输入图片的边缘进行填充,便于对边缘像素进行卷积处理。间隔既可以是一个数,也可以是元组(padH, padW)。前者是横向填充的元素数,后者是纵向填充的元素数。
dilation
groups
结构/层
可以把每个函数看作一个层。
卷积层(Convolution Layer)
torch.nn提供了torch.nn.function中各功能的简化版本。
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
conv_arithmetic/README.md at master · vdumoulin/conv_arithmetic (github.com)
in_channels:输入通道数
out_channels:输出通道数
即卷积核个数。
kernel_size:卷积核尺寸。可变量,会在训练过程中自行改变。
stride:步进数
padding:边缘补充
dilation:让卷积核的各元素之间间隔一定距离。用于空洞卷积。

groups:用于分组卷积
bias:偏置。
池化层(Pooling Layer)
池化层将一个窗口内的所有信息浓缩为一个输出。它一般在卷积后进行,输入和输出的通道相同,不可改变。因此,输出尺寸会减小,参数减小,助于减少过拟合、提高性能。
卷积核平移的过程,可看作滑动窗口过程。卷积核就是窗口。
对于最大池化(Max Pooling)操作,它取一个窗口内最大的值输出,然后步进。
MaxPool2d(kernel_size, stride=None, padding=0*, dilation=1*, return_indices=False*, ceil_mode=False)
return_indices:
ceil_mode:True时,使用ceil模式(允许出界);否则使用floor模式(出界池化丢弃)。
stride:池化核的步长默认为核大小
平均池化(Mean Pooling)操作计算窗口内平均值输出,然后步进。
填充层(Padding Layer)
类似于卷积和池化操作中的Padding参数。不同的是,Padding只能填充0,而填充层可以填充其他常数。
非线性激活(Non-linear Activations)
线性整流函数(ReLU)
torch.nn.ReLU(x):等效于max(0,x)。
inplace参数(bool):为True则修改传入值;否则传出新值,传入值不变。
Sigmoid函数
torch.nn.Sigmoid(x):等效于:1/(1+exp(-x))。
正则化层(Normalization Layer)
用于提高网络性能。
pytorch中对BatchNorm2d()函数的理解-CSDN博客
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
num_features:通道数。
eps:稳定值,避免分母为0,默认为1e-5。
momentum:将历史batch的均值与方差的影响延续到当前batch。
affine:True时,给定可以学习的系数矩阵Gamma和Beta。
线性层(Linear Layer)
torch.nn.Linear(in_features, out_features, bias=True)
对输入施加线性变换: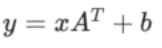
feature:特征。对事物进行分类或识别的本质就是提取特征。
在神经网络中,in_features指的是输入的数组。out_features则反之。
在Linear函数中,前两个参数分别是输入数组的元素个数和输出数组的元素个数。
丢弃层(Dropout Layer)
防止过拟合。
torch.nn.Dropout2d(p=0.5, inplace=False)
随机将某些元素按p的概率设为0。
嵌入层(Embedding Layer)
损失函数
损失函数(Loss Function)用于衡量实际输出与预期输出之间的差距,并用误差值指导模型进行进一步训练学习(即反向传播)。
L1Loss()
torch.nn.L1Loss(input, tartget, reduction='mean')
input和target的形状为(*, *)。输出一个标量。
reduction:处理方式。‘mean’则将每个元素的MAE相加并处以元素数量。‘sum’只相加。
比较每个元素的平均绝对误差(Mean Absolute Error, MAE)。
output = (|x - x’|+|y - y’| + …)/N
SmoothL1Loss()
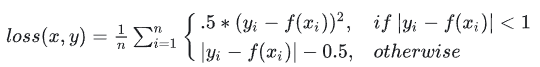
torch.nn.SmoothL1Loss(reduction='mean', beta=1.0)
平滑版的L1Loss。
当MAE小于1时,返回MSE的0.5倍;否则返回MAE-0.5。结合了L1和MSE的部分优点,适合多数情况。
MSELoss()
torch.nn.MSELoss(reduction='mean')
input和target的形状为(*, *)。输出一个标量。
比较每个元素的均方差。
output = (|x - x’|^2+|y - y’|^2 + …)/N
CrossEntropyLoss()
torch.nn.CrossEntropyLoss(weight=None, ignore_index=-100, reduction='mean', label_smoothing=0.0)
比较预期输出和实际输出的交叉熵。在分类问题中常用。
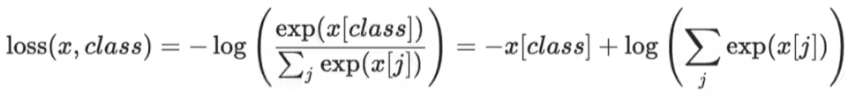
input的形状需要是(N, C)或(C, C),其中N为batch_size,C为分类的类别数。
反向传播
对损失函数的结果调用backward()子方法即可。
反向传播用于计算损失函数梯度。得到梯度以后,使用优化器对参数进行更新。
优化器
torch.optim — PyTorch main documentation
以torch.optim.SGD()为例:
- 实例化优化器对象:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)- model.parameters():nn.Module的parameters()函数。
- lr:学习速率。一般训练前期设置为大数值,训练后期设置为小数值。
- 每次取数据都要设置
optimizer.zero_grad()。 - 进行反向传播后,调用
optimizer.step()
对dataset的每一次遍历就是一次训练过程,称为一个epoch。
现有网络
以vgg16为例。
1 | |
模型
保存
方式一:torch.save(model_var_name, path):将模型结构以及参数保存为文件。
注意path添加后缀,通常为.pth。
方式二:torch.save(model_var_name.state_dict(), path):仅保存模型参数(推荐)。
注意path添加后缀,通常为.pkl。
读取
torch.load(path):对应保存方式一。
model_var_name.load_state_dict():对应保存方式二。
训练
定义网络结构
1 | |
获取、读取数据集 | 训练
1 | |
测试
1 | |