本文最后更新于 2024年8月9日 下午
逐渐深入…
高级GLSL
内建变量
顶点着色器
gl_PointSize:float输出变量,用于控制渲染GL_POINTS型图元时,点的大小。可以用于粒子系统。将其设置为gl_Position.z时,可以使点的距离越远,距离越大,创造出类似“近视眼看远处灯光”的效果。
gl_VertexID:int型输入变量(只读),存储了正在绘制顶点的ID(或索引ID,当使用glDrawElements时)。
片段着色器
gl_FragCoord:vec4型输出变量。存储了屏幕空间坐标(x、y,以窗口左下角为原点)和图元深度值(z,0-1)。常用于获取深度值,还有把窗口分为两部分进行不同渲染输出(RTX-ON/OFF)。
gl_FrontFacing:bool型输入变量。标记了当前图元是否为正面。用于对图元的正反面做不同处理。
gl_FragDepth:float型输出变量。用于手动设置片段的深度值。在片段着色器中出现后,Early-Z将被禁用。
接口块
我们使用in、out关键字在着色器之间传递数据。除了单个变量外,这两个关键字也可以用来传递与结构体相似的接口块(Interface Block)。
1
2
3
4
5
|
out VS_OUT
{
vec2 TexCoords;
} vs_out;
|
1
2
3
4
|
in VS_OUT{
vec2 TexCoords;
} fs_in;
|
使用实例名.成员变量访问成员变量。
在之前的程序中,我们每次渲染迭代都需要手动设置view、proj等uniform。为了简化操作,我们引入Uniform缓冲对象。它同样是一种OpenGL缓冲目标,在绑定后开辟一块内存区域。
对于Uniform缓冲对象,我们只需要给Shader传递一次值。随后,Shader便会自动采集缓冲区对应内存中各变量的值,自动变化,无需我们手动设置。
GLSL中,Uniform块用于采集Uniform缓冲对象中的数据。
1
2
3
4
| layout (std140) uniform Matrices{
mat4 proj;
mat4 view;
};
|
其中,layout(std140)指定了Uniform块布局。默认情况下,Uniform块布局是Shared型,这类布局的各变量偏移量会随设备和系统的不同而变化。但我们希望Uniform块中各变量的偏移量能被手工计算出,以便让块内各变量能与UBO中各变量相对应。std140布局便是我们需要的。
在std140布局中,每个变量都有一个基准对齐量(Base Alignment),它是一个变量在Uniform块中占据的空间。每个变量还有一个对齐偏移量(Aligned Offset),它是一个变量从块起始位置的偏移量,它必须是Base Alignment的倍数。简而言之,前者是size,后者是offset。
| 类型 |
布局规则 |
| 标量,比如int和bool |
每个标量的基准对齐量为N。 |
| 向量 |
2N或者4N。这意味着vec3的基准对齐量为4N。 |
| 标量或向量的数组 |
每个元素的基准对齐量与vec4的相同。 |
| 矩阵 |
储存为列向量的数组,每个向量的基准对齐量与vec4的相同。 |
| 结构体 |
等于所有元素根据规则计算后的大小,但会填充到vec4大小的倍数。 |
其中,4字节=1N
绑定点(Binding Point)可以理解为UBO的索引。每个绑定点都对应了一个UBO。每个UBO可以通过绑定点连接多个Uniform块。UBO的内容改变时,所有绑定了这个UBO的Uniform块都会改变。
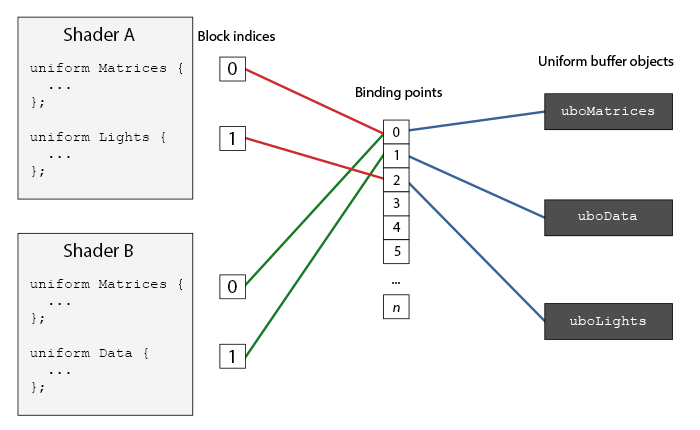
通过glGetUniformBlockIndex(shaderID, uniformName)获取uniform块索引,再通过glUniformBlockBinding(shaderID, uniformblockIndex, bindingPtrIndex)将ID为shaderID的Shader中,索引为uniformblockIndex的uniform块绑定至绑定点bindingPtrIndex。
随后,通过glBindBufferBase(GL_UNIFORM_BUFFER, bindingPtrIndex, UBO)借助句柄UBO将Uniform缓冲对象绑定至绑定点bindingPtrIndex。
也可通过glBindBufferRange(GL_UNIFORM_BUFFER, bindingPtrIndex, UBO, UBOsize)绑定。
接着,通过glBufferSubData向缓冲区分区写入数据。
1
2
3
4
| glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
int b = true;
glBufferSubData(GL_UNIFORM_BUFFER, 144, 4, &b);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
unsigned int UBO;
glGenBuffers(1,&UBO);
glBindBuffer(GL_UNIFORM_BUFFER,UBO);
glBufferData(GL_UNIFORM_BUFFER,152,NULL,GL_STATIC_DRAW);
unsigned int UBI = glGetUniformBlockIndex(shader.ID,"Matrices");
glUniformBlockBinding(shader.ID,UBI,0);
glBindBufferBase(GL_UNIFORM_BUFFER,0,UBO);
glBufferSubData(GL_UNIFORM_BUFFER,0,sizeof(glm::mat4),value_ptr(projection));
glBindBuffer(GL_UNIFORM_BUFFER,0);
|
使用UBO的好处主要在于:设置一个UBO,改变所有绑定的着色器中的块;提高着色器中允许存在的uniform数量。
几何着色器
几何着色器(Geometry Shader)位于顶点着色器和片段着色器之间,它的输入是一个图元的一组顶点,用于在将其发送到下一个着色器阶段前对其进行变换。几何着色器可以把一组顶点变化为不同的图元,也可以生成更多的顶点。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #version 330 core
layout (points) in;
layout (line_strip, max_vertices = 2) out;
void main() {
gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0);
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);
EmitVertex();
EndPrimitive();
}
|
需要注意的是,传入的图元将不会被保留。
几何着色器可以用于可视化法线,或生成毛发。
可视化法线的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNorm;
layout (location = 2) in vec2 uv;
out VS_OUT{
vec3 norm;
}vs_out;
uniform mat4 model;
uniform mat4 proj;
uniform mat4 view;
void main()
{
mat3 normalMatrix = mat3(transpose(inverse(view * model)));
vs_out.norm = normalize(vec3(vec4(normalMatrix * aNorm, 0.0)));
gl_Position = proj * view * model * vec4(aPos, 1.0);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#version 330 core
layout (triangles) in;
layout (line_strip, max_vertices = 6) out;
uniform float explodeStrength;
in VS_OUT{
vec3 norm;
}gs_in[];
out vec2 TexCoords;
void main(){
gl_Position = gl_in[0].gl_Position;
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4(gs_in[0].norm*explodeStrength,0);
EmitVertex();
EndPrimitive();
gl_Position = gl_in[1].gl_Position;
EmitVertex();
gl_Position = gl_in[1].gl_Position + vec4(gs_in[1].norm*explodeStrength,0);
EmitVertex();
EndPrimitive();
gl_Position = gl_in[2].gl_Position;
EmitVertex();
gl_Position = gl_in[2].gl_Position + vec4(gs_in[2].norm*explodeStrength,0);
EmitVertex();
EndPrimitive();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
struct Material{
sampler2D texture_diffuse1;
sampler2D texture_specular1;
float shininess;
};
uniform Material material;
void main()
{
FragColor = vec4(1.0,1.0,1.0,0.0);
}
|
实例化
对于在同一场景中使用相同顶点数据的对象(如草地中的草),可以使用实例化(Instancing)技术,用一个绘制函数让OpenGL绘制多个物体,而非循环(Drawcall: N->1)。
实例化技术本质上是减少了数据从CPU到GPU的传输次数。
使用glDrawArraysInstanced和glDrawElementsInstanced函数代替没有Instanced的版本,即可使用实例化渲染。这个版本的绘制函数接收额外的Instance Count参数,用于设置一次渲染的实例个数。
顶点着色器内建变量gl_InstanceID保存了当前渲染图元所在的实例索引。借助该变量,我们可以根据实例ID的不同改变其位置、渲染方式等。常见的方法是将其作为uniform数组的索引。
但是,程序可向着色器传递的uniform数量是有限的。之前提到的UBO是一种解决方式。但在实例化渲染中,实例化数组(Instanced Array)是更好的方式。
实例化数组被定义为一个顶点属性,仅在渲染一个新实例时才会更新。
定义实例化数组与定义顶点属性类似:
1
2
3
4
| #version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
|
1
2
3
4
5
6
7
8
9
10
| unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
|
可以看到,唯一的区别在于glVertexAttribDivisor(AttribIdx, Count)函数。这个函数定义了什么时候更新顶点属性的内容到新一组数据。Count参数为0时,每次顶点着色器运行都更新,即默认的方式;参数为1时,运行到每个实例时更新;参数为2时,每两个实例更新,以此类推。
以绘制十万个小行星为例:
首先,修改顶点着色器,便于实例化数组传入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| #version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNorm;
layout (location = 2) in vec2 uv;
layout (location = 3) in mat4 instanceMatrix;
uniform mat4 proj;
uniform mat4 view;
out vec3 norm;
out vec3 fragPos;
out vec2 TexCoords;
void main()
{
gl_Position = proj * view * instanceMatrix * vec4(aPos, 1.0);
fragPos = (instanceMatrix*vec4(aPos,1.0f)).xyz;
norm = mat3(transpose(inverse(instanceMatrix)))*aNorm;
TexCoords = uv;
}
|
然后,配置顶点属性,传入数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| unsigned int buffer;
glGenBuffers(1, &buffer);
glBindBuffer(GL_ARRAY_BUFFER, buffer);
glBufferData(GL_ARRAY_BUFFER, ROCK_AMOUNT * sizeof(glm::mat4), &rockMatrices[0], GL_STATIC_DRAW);
for(unsigned int i = 0; i < rock.meshes.size(); i++)
{
unsigned int VAO = rock.meshes[i].VAO;
glBindVertexArray(VAO);
GLsizei vec4Size = sizeof(glm::vec4);
glEnableVertexAttribArray(3);
glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)0);
glEnableVertexAttribArray(4);
glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(vec4Size));
glEnableVertexAttribArray(5);
glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(2 * vec4Size));
glEnableVertexAttribArray(6);
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(3 * vec4Size));
glVertexAttribDivisor(3, 1);
glVertexAttribDivisor(4, 1);
glVertexAttribDivisor(5, 1);
glVertexAttribDivisor(6, 1);
glBindVertexArray(0);
}
|
然后,绘制模型:
1
2
3
4
5
6
7
| for(unsigned int i = 0; i < rock.meshes.size(); i++)
{
glBindVertexArray(rock.meshes[i].VAO);
glDrawElementsInstanced(
GL_TRIANGLES, rock.meshes[i].indices.size(), GL_UNSIGNED_INT, 0, ROCK_AMOUNT
);
}
|
抗锯齿
锯齿现象又称走样(Aliasing),抗锯齿技术又称反走样(Anti-aliasing)。
超采样抗锯齿(Super Sample Aniti-aliasing, SSAA)使用比正常分辨率更高的分辨率渲染常见,当图像输出在帧缓冲更新时,下采样(Downsample)到正常分辨率。额外的分辨率用来防止走样的产生。但由于渲染分辨率的提高,性能开销将变大。NxSSAA指的就是把原分辨率放大N倍渲染后降采样的SSAA。
多重采样抗锯齿(Multisample Aniti-aliasing, MSAA)是较为常见的抗锯齿方法。
光栅器是位于最终处理过的顶点之后到片段着色器之前所经过的所有的算法与过程的总和。光栅器会将一个图元的所有顶点作为输入,并将它转换为一系列的片段。顶点坐标与片段之间几乎永远也不会有一对一的映射,所以光栅器必须以某种方式来决定每个顶点最终所在的片段/屏幕坐标。
每个像素中心包含有一个采样点(Sample Point),当采样点位于三角形内部时,这个采样点对应的像素就会生成一个片段。
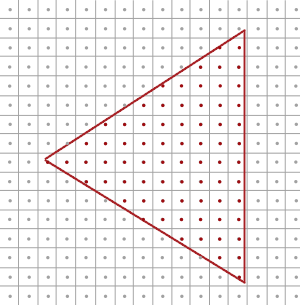
MSAA把像素的单一采样点变为多个按特定图案排列的四个子采样点(Subsample)。

无论三角形覆盖了多少子采样点,每个像素点都只会运行一次片段着色器。最终输出的片段依然位于像素中央,其y暗色由覆盖的子采样点数量决定。以4xMSAA为例,当三角形覆盖了一个像素的2个采样点时,其颜色就是0.5*三角形颜色+0.5*背景色。
本质上其实是每个子采样点都存储了颜色数据,在为像素计算片段颜色时将四个子采样点中的颜色做平均。
使用MSAA后,每个像素中都需要存储特定数量的颜色值。OpenGL中,多重采样缓冲(Multisample Buffer)用于存储特定数量的多重采样样本,替代原来的颜色缓冲。
使用glfwWindowHint(GLFW_SAMPLES,4)创建4x的多重采样缓冲。GLFW将自动为每个子采样点创建深度和样本缓冲,意味着所有缓冲的大小都增加了四倍。
使用glEnable(GL_MULTISAMPLE)开启MSAA。
离屏MSAA
当我们使用自己的帧缓冲时,需要手动生成多重采样缓冲。与帧缓冲类似,有纹理附件和渲染缓冲对象两种方式。
纹理附件
1
2
3
4
| glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
|
渲染缓冲对象
1
| glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
|
绑定到多重采样帧缓冲后,任何绘制调用都会由光栅其负责多重采样运算。我们得到的多重采样缓冲包含了颜色、深度与模板缓冲。多重采样缓冲
多重采样缓冲不能直接用于着色器采样或深度、模板测试。因此,我们在绑定多重采样缓冲并完成绘制后,需要通过glBlitFrameBuffer函数将颜色等缓冲传递到其他帧缓冲上。例如,我们想把完成多重采样后的画面传输到默认帧缓冲上,进而显示在窗口上:
1
2
3
| glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
|
再比如说,我们向把完成多重采样的画面作为一个2D纹理,用于后处理等操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| unsigned int msFBO = CreateFBOWithMultiSampledAttachments();
...
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, screenTexture, 0);
...
while(!glfwWindowShouldClose(window))
{
...
glBindFramebuffer(msFBO);
ClearFrameBuffer();
DrawScene();
glBindFramebuffer(GL_READ_FRAMEBUFFER, msFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, intermediateFBO);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
glBindFramebuffer(GL_FRAMEBUFFER, 0);
ClearFramebuffer();
glBindTexture(GL_TEXTURE_2D, screenTexture);
DrawPostProcessingQuad();
...
}
|
自定义抗锯齿
GLSL中,sampler2DMS类型的uniform与texelFetch函数相结合可以用于获取每个子样本的颜色值:
1
2
| uniform sampler2DMS screenTextureMS;
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, 3);
|