本文最后更新于 2024年11月4日 下午
数学
向量
正交
若向量集v0,...,vn−1中的每个向量都相互正交且具有单位长度,则称该集合是规范正交的。
图形学中,规范正交集会由于数值精度的问题逐渐非正交规范化,此时就需要通过正交化手段使之成为规范正交集。
通过将向量A减去其在另一向量B的正交投影,可以得到与向量B正交的向量A分量C。随后,将C和B规范化单位为向量,即可得到规范正交集。
类似的,对于三维向量,先用A减去其在B上的正交投影,再用C依次减去其在A、B上的正交投影,再规范化为单位为向量,即可。
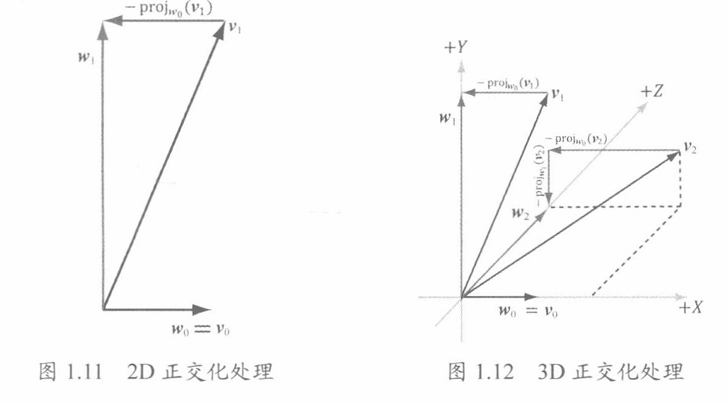
二维:w1=v1−projw0(v1)
三维:w1=v1−projw0(v1);w2=v2−projw0(v2)−projw1(v2)
高维向量依此类推。该操作被称为格拉姆-施密特正交化。
使用叉乘的三维向量集规范正交化步骤:
- 令w0=∣∣v0∣∣v0
- 令w2=∣∣w0×v1∣∣w0×v1
- 令w1=w2×w0
叉乘
叉乘计算的是与两个参数向量都正交的第三个向量。
若u=(ux,uy,uz),v=(vx,vy,vz),则有:
w=u×v=(uyvz−uzvy,uzvx−uxvz,uxvy−uyvx)
对于叉积,有:u×v=−v×u
DirectXMath
为Windows SDK的一部分,专用于DX程序3D数学计算。
头文件:DirectXMath.h、DirectXPackedVector.h。
前者代码处于DirectX命名空间,后者位于DirectX::PackedVector内。
应当开启快速浮点模型。路径:工程属性-配置属性-C/C+±代码生成-浮点模型。
向量类型
原则:
-
对于局部、全局向量变量,使用XMVECTOR
-
对于类中的数据成员,使用XMFLOAT2、XMFLOAT3、XMFLOAT4
-
在加载类中向量数据成员前,通过加载函数将XMFLOATn类型转换为XMVECTOR。
-
使用XMVECTOR进行向量运算。
-
通过存储函数将XMVECTOR转换为XMFLOATn。
-
带有const修饰符的常量XMVECTOR应当用XMVECTORRF32类型表示。
加载方法
XMVECTOR XMLoadFloat2(const XMFLOAT2 *pSource)
其余多维向量同理。
使用float XMVectorGetX(FXMVECTOR V)获取XMVECTOR中某特定分量。
存储方法
void XMStoreFloat2(XMFLOAT2 *pDestination, FXMVECTOR V)
其余同理。
使用XMVECTOR XMVectorSetX(FXMVECTOR V, float x)设置XMVECTOR中某一分量,其余同理。
参数传递
为了在所有平台/编译器上都能明确可用寄存器传送的XMVECTOR函数参数数量,使用FXMVECTOR、GXMVECTOR、HXMVECTOR、CXMVECTOR作为实际传递的向量参数类型。此外,当参数包含上述四类型中的任意个时,均需要在函数前加上XM_CALLCONV调用约定注解。
传递规则:
- 前3个XMVECTOR参数应当用类型
FXMVECTOR
- 第4个XMVECTOR 参数应当用类型
GXMVECTOR
- 第5、6个XMVECTOR参数应当用类型
HXMVECTOR
- 其余的 XMVECTOR参数应当用类型
CXMVECTOR
工具函数与数据结构
圆周率相关:XM_PI、XM_2PI、XM_1DIVPI、XM_1DIV2PI、XM_PIDIV2、XM_PIDIV4
角度弧度相关:XMCovertToRadians(float fDegrees)、XMConvertToDegrees(float fRaidnas)
大小比较相关:XMMin、XMMax
设置XMVECTOR相关:XMVectorZero()、XMVectorSplatOne()、XMVectorSet(float x, float y, float z, float w)、XMVectorReplicate(float value)、XMVectorSplatX(FXMVECTOR V)、XMVectorSplatY(FXMVECTOR V)…
向量函数相关:
XMVector3Length(FXMVECTOR V)、XMVector3LengthSq(FXMVECTOR V)、XMVector3Dot(FXMVECTOR V1, FXMVECTOR V2)、XMVector3Cross(FXMVECTOR V1. FXMVECTOR V2)、XMVector3Normalize(FXMVECTOR V)
XMVector3Orthogonal(FXMVECTOR V),返回正交于V的向量、XMVector3AngleBetweenVectors(FXMVECTOR V1, FXMVECTOR V2),返回v1v2夹角
void XMVector3ComponentsFromNormal(XMVECTOR* pParallel, XMVECTOR* pPerpendicular, FXMVECTOR V, FXMVECTOR Normal),其中pParallel、pPerpendicular为返回量,前者返回projn(v),后者返回perpn(v)。
bool XMVector3Equal(FXMVECTOR V1, FXMVECTOR V2)、bool XMVectoe3NotEqual(FXMVECTOR V1, FXMVECTOR V2)
bool XMVector3NearEqual( FXMVECTOR U, FXMVECTOR V, FXMVECTOR Epsilon)用于将向量U、V在Epsilon(四个分量均为同一float值的FXMVECTOR)规定的容忍误差范围内判定是否相等。
矩阵
行列式
det[A11A21A12A22]=A11det[A22]−A12det[A21]=A11A22−A12A21
det⎣⎢⎡A11A21A31A12A22A32A13A23A33⎦⎥⎤=A11det[A22A32A23A33]−A12det[A21A31A23A33]+A13det[A21A31A22A32]
代数余子式
Cij=(−1)i+jdetAij为元素Aij的代数余子式。
将矩阵A中的每个元素都替换为改元素的代数余子式,得到矩阵A的代数余子式矩阵。
矩阵A的代数余子式的转置矩阵为矩阵A的伴随矩阵。
逆矩阵
仅有方阵具有逆矩阵。不是每个方阵都有逆矩阵,具有逆矩阵的被称为可逆矩阵,否则成为奇异矩阵。逆矩阵唯一。
A−1=detAA∗
DirectXMath
XMMATRIX用于表示4x4矩阵。它本质上是把4个XMVECTOR拼在一起的结构体。
可以使用4个XMVECTOR或者具有16个元素的float数组作为XMMATRIX的构造方法参数用于初始化,也可以使用XMMatrixSet函数使用16个float元素创建XMMATRIX实例。
与XMVECTOR类似,我们应当使用XMFLOAT4X4存储矩阵类型数据成员,仅在局部变量、全局变量和计算时使用XMMATRIX。
使用XMStoreFloat4x4(XMFLOAT4X4* pDestination, FXMMATRIX M)将XMMATRIX存储到XMFLOAT4X4中。
声明参数包含XMMATRIX的函数时,第一个XMMATRIX应当为FXMMATRIX,其余均为CXMMATRIX。
对于类的构造函数,无论出现几个XMMATRIX参数,都应当为CXMMATRIX类型,且不应使用XM_CALLCONV约定注解。
工具函数
XMMATRIX XMMatrixIdentity()
bool XMMatrixIsIdentity(FXMMATRIX M)
XMMATRIX XMMatrixMultiply(FXMMATRIX A, CXMMATRIX B)
XMMATRIX XMMatrixTranspose(FXMMATRIX M)
XMVECTOR XMMatrixDeteriminant(FXMMATRIX M),返回XMVECTOR,其值为(det M, det M, det M, det M)
XMMATRIX XMMatrixInverse(XMVECTOR* pDeterminant, FXMMATRIX M),返回M−1
变换
$ C = SRT$
其中,C为复合变换矩阵,S为缩放矩阵,R为旋转矩阵,T为平移矩阵
先缩放,再旋转,最后平移。
坐标变换
- 对于向量:
假设pA=(x,y,z),则此向量在B坐标系下的坐标为:
pb=xub+yvb+zwb
其中,ub、vb、wb分别为A坐标系中x、y、z正方向单位向量在B坐标系中的表示。
- 对于点:
pB=xuB+yvB+zwB+QB,其中QB为坐标系A原点在坐标系B中的位置。
- 使用齐次坐标统一:
(x’,y’,z’,w)=xuB+yvB+zwB+QB
改写为矩阵形式:
[x’,y’,z’,w]=[x,y,z,w]⎣⎢⎢⎢⎡uxvxwxQxuyvywyQyuzvzwzQz0001⎦⎥⎥⎥⎤
这里的4x4矩阵被称为坐标变换矩阵。
DirectXMath
构建缩放矩阵:XMMATRIX XMMatrixScaling(float ScaleX, float ScaleY, float ScaleZ);XMMATRIX XMMatrixScalingFromVector(FXMVECTOR Scale)
构建旋转矩阵:XMMATRIX XMMatrixRotationX(float Angle);XMMATRIX XMMatrixRoationAxis(FXMVECTOR Axis, float Angle) Angle单位为弧度。
构建平移矩阵:XMMATRIX XMMatrixTranslation(float OffsetX, float OffsetY, float OffsetZ);XMMATRIX XMMatrixTranslationFromVector(FXMVECTOR Offset)
对某点应用变换:XMVECTOR XMVector3TranformCoord(FXMVECTOR V, CXMMATRIX M)
对某向量应用变换:XMVECTOR XMVector3TranformNormal(FXMVECTOR V, CXMMATRIX M)
D3D基础
预备知识
COM
DX使用组件对象模型(Component Object Model,COM)进行跨语言、跨版本的兼容。COM的主要特征是以接口而非成员方法表示对象。同时,获取COM接口时,获取的将是指向该接口的ComPtr(位于wrl.h),可以视作一类智能指针,会自动进行引用计数与内存释放。
获取COM接口应当使用特定的方法(如Get)而非new关键字。同时,COM接口的引用计数并非自动完成,而是需要调用Release方法。
常用的ComPtr方法如下:
Get:返回指向COM接口的指针,常用于将指向COM接口的指针作为函数参数。GetAddressOf:返回指向COM接口的指针的地址,类似于给Get的返回值取地址。Reset:将ComPtr实例设置为null并释放所有相关引用,同时减少其指向的COM接口的引用计数。
COM接口都以字母I作为开头。
纹理格式
| 枚举名 |
说明 |
| DXGI_FORMAT_R32G32B32_FLOAT |
3个32位float变量 |
| DXGI_FORMAT_R16G16B16A16_UNORM |
4个16位float,且被映射至[0,1] |
| DXGI_FORMAT_R32_G32_UINT |
2个32位uint |
| DXGI_FORMAT_R8G8B8A8_UNORM |
|
| DXGI_FORMAT_R8G8B8A8_SNORM |
被映射至[-1,1] |
| DXGI_FORMAT_R8G8B8A8_SINT |
被映射至[-128,127] |
| DXGI_FORMAT_R8G8B8A8_UINT |
被映射至[0,255] |
| DXGI_FORMAT_R16G16B16A16_TYPELESS |
仅用于预留内存,被绑定为纹理附件后再解释数据类型 |
| DXGI_FORMAT_D32_FLOAT_S8X24_UINT |
共占64位,32位指定浮点型深度缓冲,8位uint指定模板缓冲(且映射至[0,255],剩余24位用于填充对齐 |
| DXGI_FORMAT_D32_FLOAT |
|
| DXGI_D24_UNORM_S8_UINT |
|
| DXGI_FORMAT_D16_UNORM |
|
交换链与页面转换
双缓冲(Double Buffering)用于避免画面闪烁。
存在两个缓冲区,它们交替成为前台缓冲区(Front Buffer)与后台缓冲区(Back Buffer),当后台缓冲区绘制完毕时,缓冲区A、B的指针进行交换,使得原本的后台缓冲区中的帧画面呈现在前台缓冲区上。
前后台缓冲区形成了交换链(Swap Chain),在DX中使用IDXGISwapChain接口表示。该COM接口存储了两个缓冲区的纹理,也提供了修改缓冲区(ResizeBuffers)和呈现缓冲区内容(Present)的方法。
资源与描述符
CPU向GPU发出绘制命令前,需要将本次Draw Call相关的资源Bind/Link到渲染流水线上。然而,GPU资源并非与渲染流水线直接绑定,而是通过描述符(Descriptor)对GPU资源间接引用。描述符类似于一种结构体,它对送往GPU的资源进行了描述。我们通过指定描述符的方式把Draw Call需要引用的资源绑定到渲染流水线。
GPU资源本质上只是一堆数据,仅靠资源本身无法描述它的元信息(如格式等)。通过引入描述符,GPU既能了解到该资源数据的具体数据内容,又能明白该资源的含义(如该如何使用等)。
视图(View)与描述符(Descriptor)指的是同一概念。
| 描述符类型 |
说明 |
| CBV |
常量缓冲区视图 |
| SRV |
着色器资源视图 |
| UAV |
无序访问视图 |
| Sampler |
用于纹理贴图的采样器资源 |
| RTV |
渲染目标视图资源 |
| DSV |
深度/模板视图资源 |
描述符堆存有一系列描述符,用于存放特定类型的描述符实例,每种描述符都有一个描述符堆。
同一个资源可以用多种描述符来引用。一个资源如果在渲染管线的不同阶段被引用,那么它在被引用的每个阶段都需要设置独立的描述符。例如:当一个纹理需要被用作渲染目标与着色器资源时,我们就要为它分别创建 两个描述符:一个 RTV描述符和一个 SRV描述符。
描述符最好在初始化期间创建。
多重采样
DXGI_SAMPLE_DESC结构体用于指定多重采样的逐像素采样次数与质量级别,分别对应其UINT Count和UINT Quality成员。
通过结合D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS结构体与ID3D12Device::CheckFeatureSupport方法,可以查询DXGI_SAMPLE_DESC中Quality的具体意义:
1
2
3
4
5
6
7
8
9
| D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS msQualityLevels;
msQualityLevels.Format = mBackBufferFormat;
msQualityLevels.SampleCount= 4;
msQualityLevels.Flags = D3D12_MULTISAMPLE_QUALITY_LEVELS_FLAG_NONE;
msQualityLevels.NumQualityLevels = 0;
ThrowIfFailed(md3dDevice->CheckFeatureSupport(
D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS,
&msQualityLevels,
sizeof (msQualityLevels)));
|
CheckFeatureSupport的第二个参数会返回填写完毕的结构体。
创建深度缓冲时一定要添加DXGI_SAMPLE_DESC结构体。
功能级别
功能级别用于对应DX的不同版本,越高,则包含越高DX版本的新功能。使用D3D_FEATURE_LEVEL枚举表示功能级别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| D3D_FEATURE_LEVEL featureLevels[3] =
{
D3D_FEATURE_LEVEL_11_0,
D3D_FEATURE_LEVEL_10_0,
D3D_FEATURE_LEVEL_9_3
}
D3D12_FEATURE_DATA_FEATURE_LEVELS featureLevelsInfo;
featureLevelsInfo.NumFeatureLevels = 3;
featureLevelsInfo.pFeatureLevelsRequested = featureLevels;
md3dDevice->CheckFeatureSupport(
D3D12_FEATURE_FEATURE_LEVELS,
&featureLevelsInfo,
sizeof(featureLevelsInfo));
|
上面的代码会将当前设备支持的版本级别通过D3D12_FEATURE_DATA_FEATURE_LEVELS类型的featureLevelsInfo变量的MaxSupportedFeatureLevel字段(D3D_FEATURE_LEVEL类型)返回。
DXGI
DirectX图形基础结构(DirectX Graphics Infrastructure,DXGI)用于处理一些基本的底层人物,如交换链、全屏、枚举显示器、枚举纹理格式等。
IDXGIFactory是DXGI的一个关键接口,用于创建IDXGISwapChain和枚举显示适配器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void D3DApp::LogAdapters(){
UINT i=0;
IDXGIAdapter* adapter = nullptr;
std::vector<IDXGIAdapter*> adapterList;
while(mdxgiFactory->EnumAdapters(i,&adapter)!=DXGI_ERROR_NOT_FOUND){
DXGI_ADAPTER_DESC desc;
adapter->GetDesc(&desc);
std::wstring text = L"***Adapter: ";
text+=desc.Description;
text+=L"\n";
OutputDebugString(text.c_str());
adapterList.push_back(adapter);
++i;
}
for(size_t i=0;i<adapterList.size();++i){
LogAdapterOutputs(adapterList[i]);
ReleaseCom(adapterList[i]);
}
}
|
上述代码用于枚举该设备的所有显示适配器。但同时,每个显示适配器都可能会有多个显示输出,例如一块显卡连接了多个显示器。我们同样可以通过代码枚举某显示适配器的显示输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void D3DApp::LogAdapterOutputs(IDXGIAdapter* adapter){
UINT i=0;
IDXGIOutput* output = nullptr;
while(adapter->EnumOutputs(i,&output)!=DXGI_ERROR_NOT_FOUND){
DXGI_OUTPUT_DESC desc;
output->GetDesc(&desc);
std::wstring text = L"***Output:: ";
text+=desc.DeviceName;
text+=L"\n";
OutputDebugString(text.c_str());
LogOutputDisplayModes(output,DXGI_FORMAT_B8G8R8A8_UNORM);
ReleaseCom(output);
++i;
}
}
|
获取了显示输出后,我们在指定了某类格式后,便可以获取该显示输出针对该格式的所有支持的显示模式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void D3DApp::LogOutputDisplayModes(IDXGIOutput* output, DXGI_FORMAT format){
UINT count = 0;
UINT flags = 0;
output->GetDisplayModeList(format, flags, &count, nullptr);
std::vector<DXGI_MODE_DESC> modeList(count);
output->GetDisplayModeList(format, floags, &count, &modeList[0]);
for(auto& x : modeList){
UINT n = x.RefreshRate.Numerator;
UINT d = x.RefreshRate.Denomitor;
std::wstring text =
L"Width = " + std::to_wstring(x.Width) + L" " +
L"Height = " + std::to_wstring(x.Height) + L" " +
L"Refresh = " + std::to_wstring(n) + L"/" + std::to_wstring(d) + L"\n";
::OutputDebugString(text.c_str());
}
}
|
为获得最优的全屏性能,我们指定的显示模式需要与显示器支持的完全匹配。
资源驻留
多数资源不需要总是驻留在显存中。在DX11,资源驻留(Residency)由系统自动管理;在DX12中则支持手动控制。
1
2
3
| HRESULT ID3D12Device::MakeResident(UINT NumObjects, ID3D12Pageable *const *ppObject);
HRESULT ID3D12Device::Evict(UINT NumObjects, ID3D12Pageable * const *ppObjects);
|
CPU-GPU交互
DX中,CPU-GPU使用命令队列和命令列表进行交互。
命令队列由GPU维护,本质上为环形缓冲区。命令列表被CPU用于将绘制命令提交到命令队列。
当命令被提交到队列后,它不会立刻被执行。
命令队列被抽象为ID3D12CommandQueue接口,通过填写D3D12_COMMAND_QUEUE_DESC结构体来描述,然后调用ID3D12Device::CreateCommandQueue方法来创建队列。代码如下:
1
2
3
4
5
| Microsoft::WRL::ComPtr<ID3D12CommandQueue> mCommandQueue;
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&mCommanQueue)));
|
其中,IID_PPV_ARGS辅助宏用于获取COM接口实例的GUID。
通过ExecuteCommandLists方法将命令列表中的命令添加至队列。
void ID3D12CommandQueue::ExecuteCommandLists(UINT Count, ID3D12CommandList *const *ppCommandLists)
第一个参数为命令列表数组中命令列表的数量,第二个参数为指向命令列表数组中第一个元素的指针。
ID3D12GraphicsCommandList封装了一系列图形渲染命令,例如:
1
2
3
4
5
6
|
mCommandList->RSSetViewports(1, &mScreenViewport);
mCommandList->ClearRenderTargetView(mBackBufferVie, Colors::LightSteelBlue, 0, nullptr);
mCommandList->DrawIndexedInstanced(36,1,0,0,0);
|
当命令都被加入列表后,需要调用ID3D12GraphicsCommandList::Close()方法结束命令记录。该方法必须在ExecuteCommandLists方法之前调用。
记录在命令列表的命令实际上时存储在与之关联的命令分配器(Command Allocator)上,表现为ID3D12CommandAllocatorCOM接口。命令分配器由ID3D12Device接口创建:
1
| HRESULT ID3D12Device::CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE type, REFIID riid, void *ppCommandAllocator)
|
- type:指定与此命令分配器相关联的命令列表类型,有
D3D12_COMMAND_LIST_TYPE_DIRECT(存储可供GPU直接执行的命令)和D3D12-COMMAND_LIST_TYPE_BUNDLE(存储被打包的命令,一般用不到)
- riid:待创建的
ID3D12CommandAllocator的COM ID
- ppCommandAllocator:输出指向所建命令分配器的指针
命令列表自身同样由ID3D12Device接口创建:
1
2
3
4
5
6
7
8
| HRESULT ID3D12Device::CreateCommandList(
UINT nodeMask,
D3D12_COMMAND_LIST_TYPE type,
ID3D12CommandAllocator *pCommandAllocator,
ID3D12PipelineState *pInitialState,
REFIID riid,
void **ppCommandList
);
|
- nodeMask:对于单GPU系统,设为0。
- type:与分配器创建中的type相同。
- pCommandList:与所建命令列表关联的命令分配器。
- pInitialState:指定命令列表的渲染管线初始状态。
- riid
- ppCommandList
同一个命令分配器可以指派给多个命令列表,但不能同时被多个命令列表使用,只有在一个命令列表添加完毕命令并调用ExecuteCommandList执行,然后Reset后,才可以对同一命令分配器进行复用。
HRESULT ID3D12GraphicsCommandList::Reset(ID3D12CommandAllocator *pAllocator, ID3D12PipelineState *pInitialState)
此方法让命令列表恢复到初始状态,但仍然保留其中的命令。
CPU-GPU同步
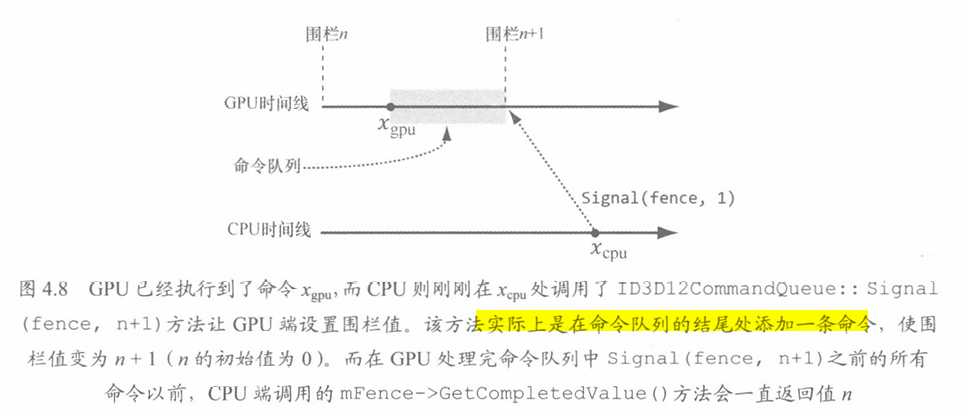
当两个对同一资源进行绘制的命令在命令队列中,且两个命令中间相隔较远,并且CPU在发出第二个命令前对资源做了修改,就会出现类似于多线程的资源竞争问题。一种解决问题的方式是强制CPU等待,直到GPU完成所有命令的处理,直到达到某个指定的围栏点(Fence Point)为止。该方式被称为刷新命令队列,通过使用围栏(Fence)来实现。
围栏用ID3D12Fence接口表示。创建方法如下:
1
2
3
| HRESULT ID3D12Device::CreateFence(UINT64 InitialValue, D3D12_FENCE_FLAGS flags, REFIID riid, void **ppFence);
ThrowIfFailed(md3dDevice->CreateFence(0,D3D12_FENCE_FLAG_NONE,IID_PPV_ARGS(&mFence)));
|
InitialValue是每个围栏对象维护的64位整数,用于表示围栏点。其初始值一般都为1,每当需要标记新围栏点时便将其加一。
使用围栏刷新命令队列的操作如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| UINT64 mCurrentFence = 0;
void D3DApp::FlushCommandQueue()
{
mCurrentFence++;
ThrowIfFailed(mCommandQueue->Signal(mFence.Get(),mCurrentFence));
if(mFence->GetCompletedValue()<mCurrentFence){
HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS);
ThrowIfFailed(mFence->SetEventOnCompletion(mCurrentFence,eventHandle));
WaitForSingleObject(eventHandle,INFINITE);
CloseHandle(eventHandle);
}
}
|
资源转换
一种常见的操作是让GPU对某资源进行先写后读(写入深度图,读取作为深度缓冲)。然而,写尚未开始便进行读取,就会导致资源危机(Resource Hazard)。为了解决这一问题,每个资源都会具备状态,并在GPU对其进行读/写操作时进行状态转换。例如,如果要对某个资源(比如纹理)执行写操作时, 需要将它的状态转换为渲染目标状态;而要对该纹理进行读操作时,再把它的状态变为着色器资源状态。在状态转换操作生效前,需要等待前一状态的所有操作执行完毕。
通过命令列表设置转换资源屏障数组,即可指定资源转换。资源屏障以D3D12_RESOURCE_BARRIER结构体表示,通过ID3D12CommandList接口的ResourceBarrier方法创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| static inline CD3DX12_RESOURCE_BARRIER Transition(
_In_ID3D12Resource* pResource,
D3D12_RESOURCE_STATES stateBefore,
D3D12_RESOURCE_STATES stateAfter,
UINT subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES,
D3D12_RESOURCE_BARRIER_FLAGS flags = D3D12_RESOURCE_BARRIER_FLAG_NONE)
{
CD3DX12_RESOURCE_BARRIER result;
ZeroMemory(&result,sizeof(result));
D3D12_RESOURCE_BARRIER &barrier = result;
result.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
result.Flags = flags;
barrier.Transition.pResource = pResource;
barrier.Transition.StateBefore = stateBefore;
barrier.Transition.StateAfter = stateAfter;
barrier.Transition.Subresource = subresource;
return result;
}
|
使用方法如下:
1
2
3
4
5
| mCommandList->ResourceBarrier(1,
&CD3DX12_RESOURCE_BARRIER::Transition(
CurrentBackBuffer(),
D3D12_RESOURCE_STATE_PRESENT,
D3D12_RESOURCE_STATE_RENDER_TARGET));
|
上述代码将显示在屏幕中的纹理从呈现状态转换到渲染目标状态。
初始化D3D
步骤如下:
- 创建
ID3D12Device接口,作为一个显示适配器的代表。该接口用于检测系统环境对功能的支持状况,且用于创建其他D3D接口对象,是一切的基础。
ID3D12Debug接口应当在ID3D12Device之前被创建,方便调试D3D程序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#if defined(DEBUG) || defined(_DEBUG)
{
ComPtr<ID3D12Debug> debugController;
ThrowIfFailed(D3D12GetDebugInterface(IID_PPV_ARGS(&debugController)));
debugController->EnableDebugLayer();
}
#endif
ThrowIfFailed(CreateDXGIFactory1(IID_PPV_ARGS(&mdxgiFactory)));
HRESULT hardwareResult = D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PRV_ARGS(&md3dDevice));
if(FAILED(hardwareResult)){
ComPtr<IDXGIAdapter> pWarpAdapter;
ThrowIfFailed(mdxgiFactory->EnumWarpAdapter(IID_PPV_ARGS(&pWarpAdapter)));
ThrowIfFailed(D3D12CreateDevice(pWarpAdapter.Get(),D3D_FEATURE_LEVEL_11_0,IID_PPV_ARGS(&md3dDevice)));
}
|
- 创建围栏并获取描述符大小
完成设备创建后,我们便可以利用创建好的ID3D12Device接口初始化其他必要的接口了。
围栏在CPU-GPU同步中至关重要,任何D3D程序都需要使用围栏机制。
1
| ThorwIfFailed(md3dDevice->CreateFence(0,D3D12_FENCE_FLAG_NONE,IID_PPV_ARGS(&mFence)));
|
此外,要想让描述符正常工作,需要获取各类描述符的描述符堆容量在当前GPU平台上的大小。这是因为不同GPU平台的描述符大小各不相同。
1
2
3
| mRtvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
mDsvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_DSV);
mCbvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_CBV);
|
- 检测对4X MSAA质量级别的支持
前面已经提到,不同平台对MSAA的质量级别有不同的定义,我们需要查询,以填写MSAA结构体。
1
2
3
4
5
6
7
8
9
| D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS msQualityLevels;
msQualityLevels.Format = mBackBufferFormat;
msQualityLevels.SampleCount = 4;
msQualityLevels.Flags = D3D_MULTISAMPLE_QUALITY_LEVELS_FLAG_NONE;
msQualityLevels.NumQualityLevels = 0;
ThrowIfFailed(md3dDevice->CheckFeatureSupport(D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS),&msQualityLevels,sizeof(msQualityLevels));
m4xMsaaQuality = msQualityLevels.NumQualityLevels;
assert(m4xMsaaQuality>0&&"Unexpected MSAA quality level");
|
- 创建命令队列和列表
ID3D12CommandQueue表示命令队列,ID3D12CommandAllocator表示命令分配器,ID3D12GraphicsCommandList表示命令列表。三者创建流程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| ComPtr<ID3D12CommandQueue> mCommandQueue;
ComPtr<ID3D12CommandAloocator> mCommandAloocator;
ComPtr<ID3D12GraphicsCommandList> mCommandList;
void D3DApp::CreateCommandObjects(){
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateCommandQueue(&queueDesc,IID_PPV_ARGS(&mCommandQueue)));
ThrowIfFailed(md3dDevice->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT),IID_PPV_ARGS(mDirectCmdListAlloc.GetAddressOf())));
ThrowIfFailed(md3dDevice->CreateCommandList(0,D3D12_COMMAND_LIST_TYPE_DIRECTR,mDirectCmdListAlloc.Get(),nullptr,IID_PPV_ARGS(mCommandList.GetAddressOf())));
mCommandList->Close();
}
|
- 描述并创建交换链
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| DXGI_FORMAT mBackBufferFormat = DXGI_FORMAT_R8G8B8A8_UNORM;
void D3DApp::CreateSwapChain(){
mSwapChain.Reset();
DXGI_SWAP_CHAIN_DESC swapChainDesc;
swapChainDesc.BufferCount = FrameCount;
swapChainDesc.BufferDesc.Width = mClientWidth;
swapChainDesc.BufferDesc.Height = mClientHeight;
swapChainDesc.BufferDesc.RefreshRate.Numerator = 60;
swapChainDesc.BufferDesc.RefreshRate.Denominator = 1;
swapChainDesc.BufferDesc.Format = mBackBufferFormat;
swapChainDesc.BufferDesc.ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED;
swapChainDesc.BufferDesc.Scaling = DXGI_MODE_SCALING_UNSPECIFIED;
swapChainDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
swapChainDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
swapChainDesc.OutputWindow = hwnd;
swapChainDesc.SampleDesc.Count = m4xMsaaState ? 4: 1;
swapChainDesc.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality-1) : 0;
swapChainDesc.Windowed = TRUE;
ThrowIfFailed(mdxgiFactory->CreateSwapChain(mCommandQueue.Get(),&swapChainDesc,mSwapChain.GetAddressOf()));
}
|
- 创建描述符堆
使用ID3D12DescriptorHeap表示描述符堆,使用ID3D12Device::CreateDescriptorHeap方法来创建。
一般而言,有多少个缓冲区就需要创建多少个RTV,而DSV仅需创建一个。一个描述符堆可以存储多个描述符,我们仅需为每个类别的描述符创建一个描述符堆即可。
1
2
3
4
5
6
7
8
9
10
| ComPtr<ID3D12DescriptorHeap> mRtvHeap;
ComPtr<ID3D12DescriptorHeap> mDsvHeap;
void D3DApp::CreateRtvAndDsvDescriptorHeaps(){
D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc;
rtvHeapDesc.NumDescriptors = SwapCahinBufferCount;
rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
rtvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(&rtvHeapDesc, IID_PPV_ARGS(mRtvHeap.GetAddressOf())));
}
|
我们使用句柄引用描述符,通过ID3D12DescriptorHeap::GetCPUDescriptorHandleForHeapStart获取描述符堆中第一个描述符的句柄。
我们可以使用下面的自定义函数获取当前后台缓冲区的RTV和DSV:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| D3D12_CPU_DESCRIPTOR_HANDLE D3DApp::CurrentBackBufferView() const
{
return CD3DX12_CPU_DESCRIPTOR_HANDLE(
mRtvHeap->GetCPUDescriptorHandleForHeapStart(),
mCurrBackBuffer,
mRtvDescriptorSize);
)
}
D3D12_CPU_DESCRIPTOR_HANDLE D3DApp::DepthStencilView() const
{
return mDsvHeap->GetCPUDescriptorHandleForHeapStart();
}
|
- 创建渲染目标视图(RTV)
资源不能直接与渲染管线中的阶段直接绑定,需要描述符对资源的元数据进行描述,方便GPU判断资源的类型等。
缓冲区是一种资源,可以用ID3D12Resource表示。
以将后台缓冲区绑定至渲染管线的输出合并阶段为例,首先我们需要获取位于交换链的缓冲区资源:
1
2
3
4
5
6
7
8
9
10
11
12
| ComPtr<ID3D12Resource> mSwapChainBuffer[SwapChainBufferCount];
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(mRtvHeap->GetCPUDescriptorHandleForHeapStart());
for(UINT i = 0;i<SwapChainBufferCount;i++){
ThrowIfFailed(mSwapChain->GetBuffer(i,IID_PPV_ARGS(&mSwapChainBuffer[i])));
md3dDevice->CreateRenderTargetView(mSwapChainBuffer[i].Get(),nullptr,rtvHeapHandle);
rtvHeapHandle.Offset(1,mRtvDescriptorSize);
}
|
- 创建深度/模板缓冲区及视图
深度缓冲区本质上就是2D纹理。纹理同样也是GPU资源,通过D3D12_RESOURCE_DESC结构体描述,通过ID3D12Device::CreateCommittedResource创建。
D3D12_RESOURCE_DESC包含下列成员:
- Dimension:资源维度,枚举,以
D3D12_RESOURCE_DIMENSION_开头,有UNKNOWN、BUFFER、TEXTURE1D、TEXTURE2D、TEXTURE3D五种
- Width:纹理宽度,单位纹素
- Height:纹理高度
- DepthOrArraySize:以纹素为单位表示的纹理深度,或纹理数组大小
- MipLevels:MipMap层级数,对于DS缓冲区来说仅能有一个
- Format:指定纹理格式
- SampleDesc:MS质量级别与采样倍率,必须与渲染目标的MS设置一致
- Layout:指定纹理布局
- Flags:深度/缓冲须指定为
D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL
GPU 资源都存于堆(heap)中,其本质是具有特定属性的 GPU 显存块。ID3D12Device:: CreateCommittedResource方法将根据我们所提供的属性创建一个资源与一个堆,并把该资源提交 到这个堆中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
D3D12_RESOURCE_DESC depthStencilDesc;
depthstencilDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D;
depthstencilDesc.Alignment = 0;
depthstencilDesc.Width = mClientWidth;
depthStencilDesc.Height = mClientHeight;
depthstencilDesc.DepthOrArraySize = 1;
depthstencilDesc.MipLevels = 1;
depthstencilDesc.Format = mDepthStencil Format;
depthstencilDesc.SampleDesc.Count = m4xMsaaState ? 4 : 1;
depthstencilDesc.SampleDesc.Quality =m4xMsaaState ?(m4xMsaaQuality - 1):0;
depthStencilDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN;
depthstencilDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL;
D3D12_CLEAR_VALUE optClear;
optClear.Format = mDepthstencilFormat;
optclear.Depthstencil.Depth =1.0f;
optClear.DepthStencil.Stencil = 0;
ThrowIfFailed(md3dDevice->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&depthstencilDesc,
D3D12_RESOURCE_STATE_COMMON,
&optClear,
IID_PPV_ARGS(mDepthStencilBuffer.GetAddressOf())));
md3dDevice->CreateDepthStencilView(
mDepthStencilBuffer.Get();
nullptr,
DepthStencilView());
mCommandList->ResourceBarrier(
1,
&CD3D12_RESOURCE_BARRIER::Transition(
mDepthStencilBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON,
D3C12_RESOURCE_STATE_DEPTH_WRITE);
)
)
|
- 设置视口
视口(Viewport)为后台缓冲区的渲染区域,通过D3D12_VIEWPORT结构体描述。该结构体包含成员:
FLOAT TopLeftX、FLOAT TopLeftY、FLOAT Width、FLOAT Height:定义了视口矩形相对于后台缓冲区的绘制范围的偏移值FLOAT MinDepth、FLOAT MaxDepth:将深度值从[0,1]映射到[MinDepth,MaxDepth],可以实现一些特效,通常分别为0和1
使用ID3D12GraphicsCommandList::RSSetViewports方法,借助D3D12_VIEWPORT结构体来设置视口。
1
2
3
4
5
6
7
8
9
| D3D12_VIEWPORT vp;
vp.TopLeftX= 0.0f;
vp.TopLeftY = 0.0f;
vp.Width = static_cast<float>(mclientWidth);
vp.Height = static_cast<float>(mClientHeight);
vp.MinDepth = 0.0f;
vp.MaxDepth = 1.0f;
mCommandList->RSSetViewports(1,&vp);
|
命令列表被重置后,视口也需要重新设置。
- 设置裁剪矩形
裁剪矩形用于裁剪操作。在矩形之外的像素不会被渲染,从而提升性能。
无特殊情况时,视口和裁剪矩形都应当占据整个窗口。
使用D3D12_RECT结构体定义裁剪矩形。它包含left、top、right、bottom四个LONG型成员。
使用ID3D12GraphicsCommandList::RSSetScissorRects设置裁剪矩形:
1
2
| mScissorRect={0,0,mclientwidth/2,mClientHeight/2};
mCommandList->RSSetscissorRects(1,&mScissorRect);
|