Vulkan 简单学习笔记¶
实例与设备设置¶
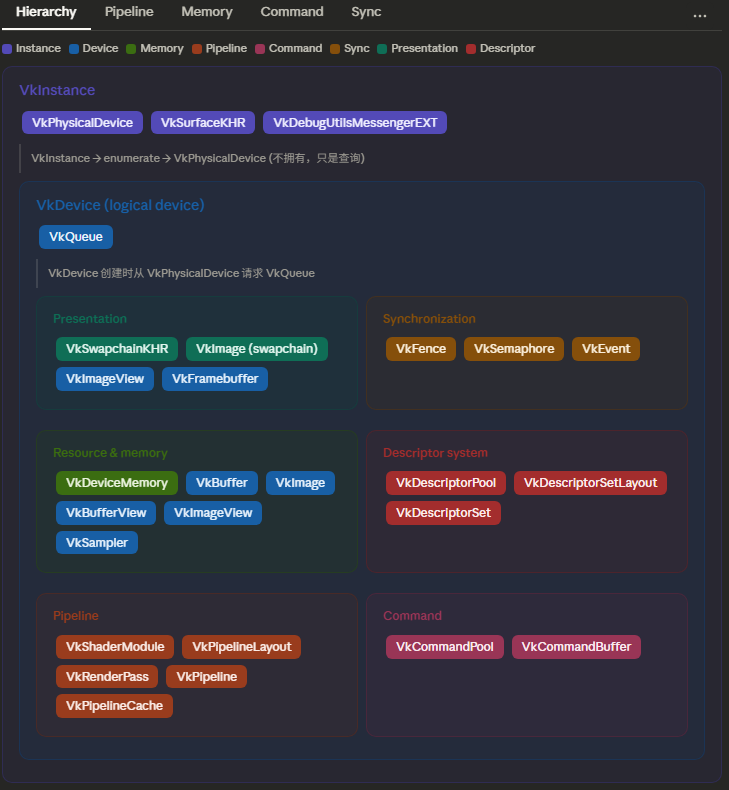
Vulkan实例(VkInstance)是应用程序与Vulkan之间的桥梁。Vulkan程序运行的第一步是创建Vulkan实例。
创建Vulkan实例¶
先填写VkApplicationInfo,再填写VkInstanceCreateInfo,最后调用vkCreateInstance来创建实例。
VkApplicationInfo appInfo = {};
appInfo.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
appInfo.pApplicationName = "Hello Triangle";
appInfo.apiVersion = VK_API_VERSION_1_3;
注意,这是Minimal的
VkApplicationInfo结构体填写方式。
随后,指定要启用的实例级扩展。实例级扩展是平台相关的,我们可以从glfw或SDL等库中获取所需的扩展名称。
uint32_t glfwExtensionCount = 0;
const char** glfwExtensions = glfwGetRequiredInstanceExtensions(&glfwExtensionCount);
接下来,创建VkInstanceCreateInfo结构体,并将之前填写的应用程序信息和扩展信息传入。
VkInstanceCreateInfo createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
createInfo.pApplicationInfo = &appInfo;
createInfo.enabledExtensionCount = glfwExtensionCount;
createInfo.ppEnabledExtensionNames = glfwExtensions;
chk(vkCreateInstance(&createInfo, nullptr, &instance));
这里的
chk函数是一个错误检查函数,用于检查Vulkan函数调用的返回值是否为VK_SUCCESS。
物理设备选择¶
当一台电脑上有多张显卡,或者同时存在集显和独显时,就存在多个Vulkan物理设备。我们需要选择一个物理设备来使用。
在Vulkan中,“选择”这一过程是通过枚举物理设备实现的:
uint32_t deviceCount = 0;
chk(vkEnumeratePhysicalDevices(instance, &deviceCount, nullptr));
std::vector<VkPhysicalDevice> devices(deviceCount);
chk(vkEnumeratePhysicalDevices(instance, &deviceCount, devices.data()));
我们可以通过vkGetPhysicalDeviceProperties函数获取每个物理设备的属性信息:
VkPhysicalDeviceProperties2 deviceProperties;
deviceProperties.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_PROPERTIES_2;
vkGetPhysicalDeviceProperties2(device, &deviceProperties);
std::cout << "Device Name: " << deviceProperties.properties.deviceName << std::endl;
除了deviceName外,还有deviceType、vendorID、deviceID等属性可以参考。
队列¶
Vulkan中的命令提交是通过队列(Queue)来完成的。
队列不能简单理解为数据结构中的队列。Vulkan中,队列是对硬件功能的抽象。
队列按族进行划分,同族的队列具有相同的功能。不同GPU可能有不同的队列族和队列数量。
我们通过vkGetPhysicalDeviceQueueFamilyProperties函数获取物理设备的队列族信息:
uint32_t queueFamilyCount = 0;
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, nullptr);
std::vector<VkQueueFamilyProperties> queueFamilies(queueFamilyCount);
vkGetPhysicalDeviceQueueFamilyProperties(device, &queueFamilyCount, queueFamilies.data());
队列族的queueFlags字段表示该队列族支持的功能。假设我们要判断一个队列族是否支持图形功能:
if (queueFamilies[i].queueFlags & VK_QUEUE_GRAPHICS_BIT) {
// 该队列族支持图形功能
}
此外,还需要查看队列族是否支持呈现功能。我们可以使用vkGetPhysicalDeviceSurfaceSupportKHR函数:
VkBool32 presentSupport = false;
vkGetPhysicalDeviceSurfaceSupportKHR(device, i, surface, &presentSupport);
if (presentSupport) {
// 该队列族支持呈现功能
}
通过填写VkDeviceQueueCreateInfo结构体,我们可以指定要创建的逻辑设备需要哪些队列:
float queuePriority = 1.0f;
VkDeviceQueueCreateInfo queueCreateInfo = {};
queueCreateInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueCreateInfo.queueFamilyIndex = i; // 队列族索引
queueCreateInfo.queueCount = 1; // 创建一个队列
queueCreateInfo.pQueuePriorities = &queuePriority; // 队列优先级
创建逻辑设备¶
物理设备是实际的GPU,逻辑设备则是我们与物理设备交互的接口。创建逻辑设备时,我们需要指定要使用的队列和要启用的设备级扩展。
通常,这里我们只需要VK_KHR_swapchain扩展来支持交换链功能:
std::vector<const char*> deviceExtensions = {
VK_KHR_SWAPCHAIN_EXTENSION_NAME
};
还有另一些我们需要的功能,已经集成在Vulkan 1.3核心规范中,不需要单独启用扩展:
VkPhysicalDeviceVulkan12Features enabledVk12Features{
.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_VULKAN_1_2_FEATURES,
.descriptorIndexing = true,
.shaderSampledImageArrayNonUniformIndexing = true,
.descriptorBindingVariableDescriptorCount = true,
.runtimeDescriptorArray = true,
.bufferDeviceAddress = true
};
const VkPhysicalDeviceVulkan13Features enabledVk13Features{
.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_VULKAN_1_3_FEATURES,
.pNext = &enabledVk12Features,
.synchronization2 = true,
.dynamicRendering = true,
};
const VkPhysicalDeviceFeatures enabledVk10Features{
.samplerAnisotropy = VK_TRUE
};
确定了要使用的队列、扩展以及需要启用的功能后,我们就可以创建逻辑设备了:
VkDeviceCreateInfo createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;
createInfo.queueCreateInfoCount = 1;
createInfo.pQueueCreateInfos = &queueCreateInfo;
createInfo.enabledExtensionCount = static_cast<uint32_t>(deviceExtensions.size());
createInfo.ppEnabledExtensionNames = deviceExtensions.data();
createInfo.pEnabledFeatures = &enabledVk10Features;
createInfo.pNext = &enabledVk13Features;
chk(vkCreateDevice(device, &createInfo, nullptr, &logicalDevice));
随后,从逻辑设备中获取创建好的队列:
vkGetDeviceQueue(logicalDevice, i, 0, &graphicsQueue);
设置VMA¶
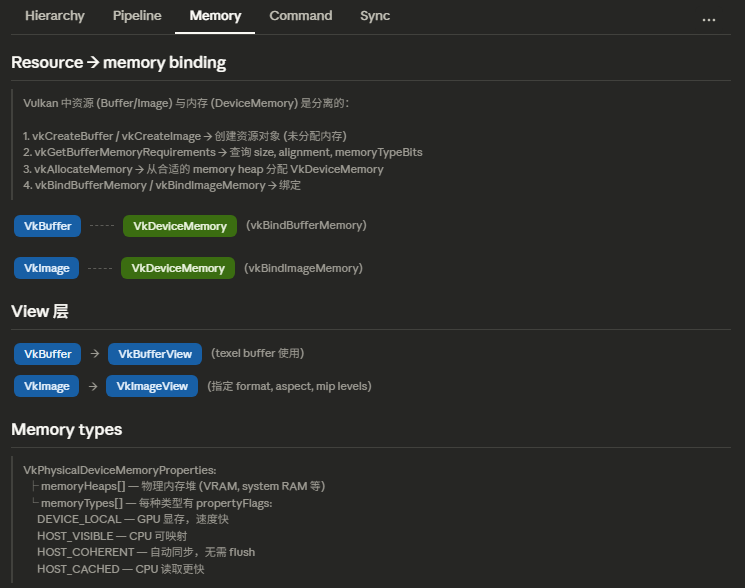
原生Vulkan的内存管理需要开发者手动管理内存分配和释放,这非常麻烦。Vulkan Memory Allocator(VMA)是一个第三方库,提供了更高层次的内存管理接口,简化了内存分配和资源绑定的过程。
在项目初始化时,我们需要创建VMA分配器:
// 传递函数指针
VmaVulkanFunctions vulkanFunctions = {};
vulkanFunctions.vkGetInstanceProcAddr = vkGetInstanceProcAddr;
vulkanFunctions.vkGetDeviceProcAddr = vkGetDeviceProcAddr;
vulkanFunctions.vkCreateImage = vkCreateImage;
VmaAllocatorCreateInfo allocatorInfo = {};
allocatorInfo.flags = VMA_ALLOCATOR_CREATE_BUFFER_DEVICE_ADDRESS_BIT;
allocatorInfo.physicalDevice = physicalDevice;
allocatorInfo.device = logicalDevice;
allocatorInfo.pVulkanFunctions = &vulkanFunctions;
allocatorInfo.instance = instance;
chk(vmaCreateAllocator(&allocatorInfo, &allocator));
窗口与渲染目标¶
表面¶
Vulkan中的表面(Surface)是一个抽象概念,表示一个可以被Vulkan渲染的目标。表面通常与窗口系统相关联,例如在Windows上是一个窗口句柄,在Linux上是一个X11或Wayland表面。
通常,我们使用第三方库(如GLFW或SDL)来创建窗口和表面:
// 先创建一个GLFW窗口
GLFWwindow* window = glfwCreateWindow(800, 600, "Vulkan Window", nullptr, nullptr);
// 然后创建Vulkan表面
VkSurfaceKHR surface;
glfwCreateWindowSurface(instance, window, nullptr, &surface);
// 保存表面属性到变量,便于后续使用
VkSurfaceCapabilitiesKHR surfaceCapabilities;
vkGetPhysicalDeviceSurfaceCapabilitiesKHR(physicalDevice, surface, &surfaceCapabilities);
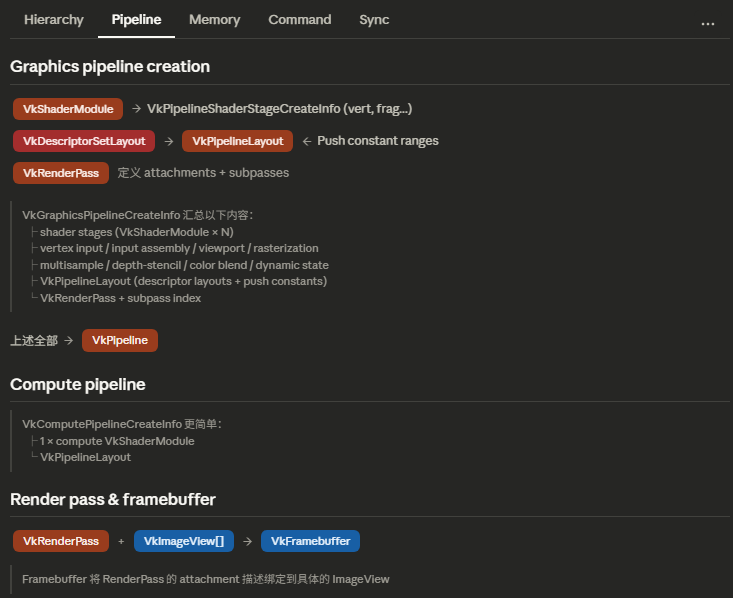
交换链¶
交换链(Swapchain)是Vulkan中用于管理帧缓冲的机制。它负责在渲染完成后将图像呈现到屏幕上。
交换链本质上是一组图像,排着队等待被渲染和呈现。我们需要根据表面属性来创建交换链。
创建交换链所需的参数较多:
const VkFormat swapchainImageFormat = VK_FORMAT_B8G8R8A8_SRGB;
VkSwapchainCreateInfoKHR createInfo = {
.sType = VK_STRUCTURE_TYPE_SWAPCHAIN_CREATE_INFO_KHR,
.surface = surface,
// 交换链中的图像数量必须至少为表面支持的最小值加1,以确保有足够的图像进行渲染和呈现
// 双缓冲则为2,三缓冲则为3
// 设备相关,需要从表面属性中获取
.minImageCount = surfaceCapabilities.minImageCount + 1,
// B8G8R8A8_SRGB配合VK_COLOR_SPACE_SRGB_NONLINEAR_KHR的组合所有平台必定支持
.imageFormat = swapchainImageFormat,
.imageColorSpace = VK_COLOR_SPACE_SRGB_NONLINEAR_KHR,
// 交换链图像的分辨率必须与表面当前的分辨率匹配
.imageExtent{.width = surfaceCapabilities.currentExtent.width, .height = surfaceCapabilities.currentExtent.height},
// 交换链图像的层数,普通为1,VR为2
.imageArrayLayers = 1,
// 交换链图像的使用方式为颜色附件
.imageUsage = VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT,
// 在图像被呈现前的预变换
.preTransform = VK_SURFACE_TRANSFORM_IDENTITY_BIT_KHR,
// 交换链图像的复合Alpha模式,表示图像如何与其他窗口内容进行混合
.compositeAlpha = VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR,
// 交换链图像的呈现模式,包含IMMEDIATE、MAILBOX、FIFO等。FIFO强制支持,MAILBOX延迟最低,IMMEDIATE可能会有撕裂
.presentMode = VK_PRESENT_MODE_FIFO_KHR,
};
chk(vkCreateSwapchainKHR(logicalDevice, &createInfo, nullptr, &swapchain));
交换链创建成功后,我们可以获取交换链中的图像。
通常,对于图像资源,我们需要为它们分配内存并绑定内存,但交换链图像由Vulkan管理,我们不需要手动分配和绑定内存。
uint32_t swapchainImageCount = 0;
vkGetSwapchainImagesKHR(logicalDevice, swapchain, &swapchainImageCount, nullptr);
std::vector<VkImage> swapchainImages(swapchainImageCount);
vkGetSwapchainImagesKHR(logicalDevice, swapchain, &swapchainImageCount, swapchainImages.data());
深度附件¶
与交换链图像不同,深度附件需要自己创建和管理。
创建深度附件的过程为:查询物理设备支持的深度格式,创建深度图像,分配内存并绑定内存,创建图像视图。
// 查询支持的深度格式
// Vulkan规范保证至少支持VK_FORMAT_D32_SFLOAT_S8_UINT和VK_FORMAT_D24_UNORM_S8_UINT这两种深度格式中的一个
std::vector<VkFormat> depthFormats = {VK_FORMAT_D32_SFLOAT_S8_UINT, VK_FORMAT_D24_UNORM_S8_UINT};
VkFormat depthFormat = VK_FORMAT_UNDEFINED;
for (VkFormat format : depthFormats) {
VkFormatProperties formatProperties;
vkGetPhysicalDeviceFormatProperties(physicalDevice, format, &formatProperties);
if (formatProperties.optimalTilingFeatures & VK_FORMAT_FEATURE_DEPTH_STENCIL_ATTACHMENT_BIT) {
depthFormat = format;
break;
}
}
// 创建深度图像
VkImageCreateInfo depthImageInfo = {
.sType = VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO,
.imageType = VK_IMAGE_TYPE_2D,
.format = depthFormat,
.extent{.width = surfaceCapabilities.currentExtent.width, .height = surfaceCapabilities.currentExtent.height, .depth = 1},
.mipLevels = 1,
.arrayLayers = 1,
.samples = VK_SAMPLE_COUNT_1_BIT,
// 让图像以GPU最优的方式进行布局和内存访问
.tiling = VK_IMAGE_TILING_OPTIMAL,
.usage = VK_IMAGE_USAGE_DEPTH_STENCIL_ATTACHMENT_BIT,
// 不关心图像的初始内容,允许Vulkan以最优的方式处理图像内存
.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED,
};
//使用VMA创建深度图像并分配内存
VmaAllocationCreateInfo depthImageAllocInfo = {
// 给此图像分配独立的内存块,避免与其他资源共享内存。大图像或频繁访问的图像建议使用独立内存。
.flags = VMA_ALLOCATION_CREATE_DEDICATED_MEMORY_BIT,
// 根据其他参数自动选择内存类型
.usage = VMA_MEMORY_USAGE_AUTO;
};
VmaAllocation depthImageAllocation;
chk(vmaCreateImage(allocator, &depthImageInfo, &depthImageAllocInfo, &depthImage, &depthImageAllocation, nullptr));
// 因为深度附件是GPU独占的,与CPU无关,所以不需要多个图像进行帧同步,直接创建一个深度图像即可。
// 创建深度图像视图
VkImageViewCreateInfo depthImageViewInfo = {
.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO,
.image = depthImage,
.viewType = VK_IMAGE_VIEW_TYPE_2D,
.format = depthFormat,
// 指定视图能访问图像的哪些部分。
// 例如,多Mip图像可以创建不同视图,每个视图访问不同的Mip级别。
.subresourceRange{
.aspectMask = VK_IMAGE_ASPECT_DEPTH_BIT,
.levelCount = 1,
.layerCount = 1
},
};
chk(vkCreateImageView(logicalDevice, &depthImageViewInfo, nullptr, &depthImageView));
资源加载与同步¶
为了尽可能减少CPU与GPU之间的相互等待,我们使用多缓冲的方式,让所有CPU和GPU共享的资源都有多个副本。这样,CPU在更新资源时可以使用一个副本,而GPU在渲染时可以使用另一个副本,从而避免了CPU和GPU之间的直接等待。
在Vulkan中,这些副本被称为飞行中的帧(In-flight Frame)。每个飞行中的帧都有自己的命令缓冲、同步对象和资源副本。
飞行中的帧越多,从渲染到呈现的延迟就越大。一般我们使用双缓冲或三缓冲来平衡性能和延迟。
CPU和GPU共享的资源有:着色器数据缓冲区(ShaderDataBuffer)和命令缓冲区(CommandBuffer)。
constexpr uint32_t MAX_FRAMES_IN_FLIGHT = 2;
std::array<ShaderDataBuffer, MAX_FRAMES_IN_FLIGHT> shaderDataBuffers;
std::array<VkCommandBuffer, MAX_FRAMES_IN_FLIGHT> commandBuffers;
着色器数据缓冲区¶
着色器数据缓冲区是一个GPU缓冲区,用于存储CPU更新的着色器数据,例如变换矩阵、材质参数等。
CPU向着色器数据缓冲区写入数据,GPU读取这些数据。GPU保证在Drawcall期间,着色器数据缓冲区的数据不会被修改。
例如,在CPU端:
struct ShaderData{
glm::mat4 model;
glm::mat4 view;
glm::mat4 projection;
glm::vec4 lightPos{0.0f, -10.0f, 10.0f, 1.0f};
uint32_t selected{1};
} shaderData{};
Vulkan 1.3新增的缓冲区设备地址功能允许我们直接在GPU上访问缓冲区内存,而不需要绑定和复制数据。使用缓冲区设备地址时,我们不需要设置描述符。
for(auto i=0;i<MAX_FRAMES_IN_FLIGHT;++i){
VkBufferCreateInfo uBufferCI{
.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO,
.size = sizeof(ShaderData),
// 通过设备地址访问缓冲区,允许GPU直接访问缓冲区内存,而不需要绑定和复制数据。
.usage = VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT,
};
VmaAllocationCreateInfo uBufferAllocCI{
.usage = VMA_MEMORY_USAGE_AUTO,
.flags =
// 当存在HOST_VISIBLE内存类型时,VMA会优先选择HOST_VISIBLE内存类型,这样CPU可以直接访问缓冲区内存,无需额外的映射步骤。
VMA_ALLOCATION_CREATE_HOST_ACCESS_SEQUENTIAL_WRITE_BIT |
// 允许VMA在HOST_VISIBLE内存类型不可用时,选择DEVICE_LOCAL内存类型,并通过Staging Buffer的方式实现CPU访问。这种方式会增加一些开销,但在某些平台上可能是唯一的选择。
VMA_ALLOCATION_CREATE_HOST_ACCESS_ALLOW_TRANSFER_INSTEAD_BIT |
// 分配完成后立即将内存映射到CPU地址空间,允许CPU直接访问缓冲区内存,无需额外的映射步骤。
// 通过VmaAllocationInfo::pMappedData指针,CPU可以直接访问缓冲区内存
VMA_ALLOCATION_CREATE_MAPPED_BIT,
};
chk(vmaCreateBuffer(allocator, &uBufferCI, &uBufferAllocCI, &shaderDataBuffers[i].buffer, &shaderDataBuffers[i].allocation, nullptr));
chk(vmaMapMemory(allocator, shaderDataBuffers[i].allocation, &shaderDataBuffers[i].mapped));
}
同步对象¶
为了检查同步相关问题,可以开启验证层的同步验证预设。
具体开启方法为:在创建Vulkan实例时,启用
VK_EXT_validation_features扩展,并在实例创建信息中指定要启用的验证功能:VkValidationFeatureEnableEXT validationFeatures[] = { VK_VALIDATION_FEATURE_ENABLE_SYNCHRONIZATION_VALIDATION_EXT }; VkValidationFeaturesEXT validationFeaturesInfo = { .sType = VK_STRUCTURE_TYPE_VALIDATION_FEATURES_EXT, .enabledValidationFeatureCount = 1, .pEnabledValidationFeatures = validationFeatures }; // VkInstanceCreateInfo结构体中设置pNext指针,指向验证功能信息结构体 createInfo.pNext = &validationFeaturesInfo;
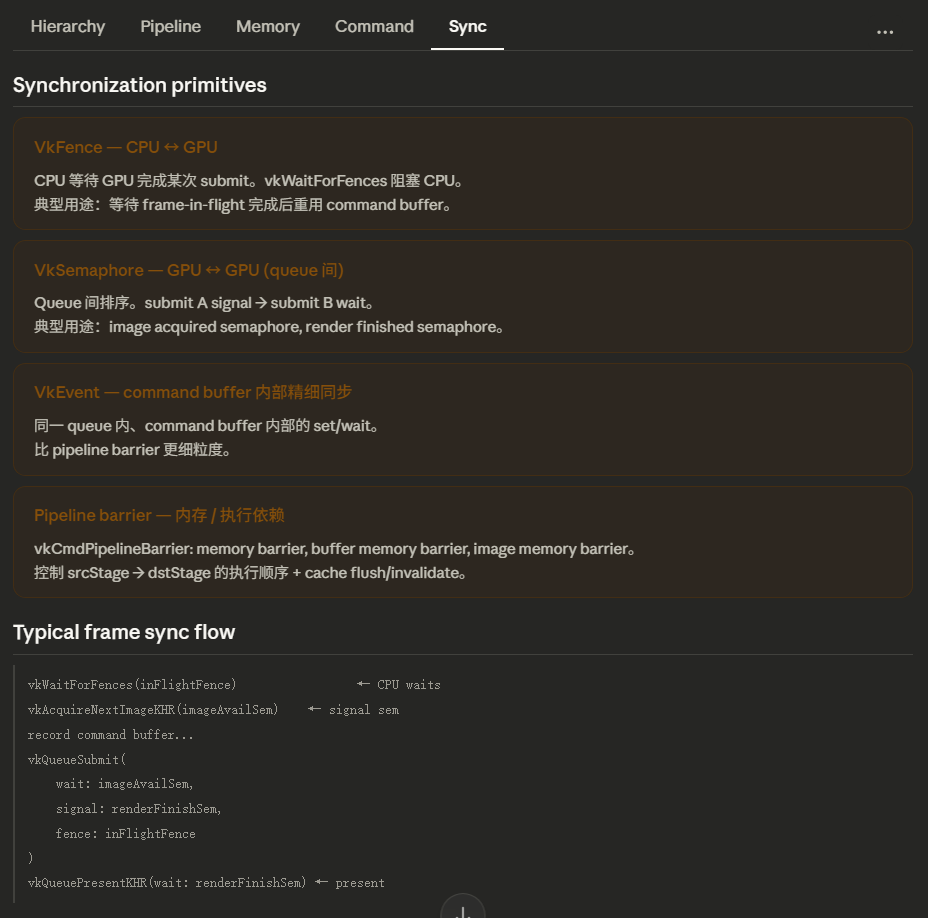
Vulkan包含下面三大同步方式:
- 栅栏(Fence):GPU通知CPU工作完成。主要用于CPU等待GPU完成某些工作的情况,例如等待GPU完成当前帧的渲染工作,才能开始下一帧的资源更新和命令录制。
CPU: vkQueueSubmit(queue, ..., fence) ← 提交命令,顺带递给GPU一面旗子
CPU: vkWaitForFences(fence) ← CPU 在这里阻塞等待
...(CPU 睡着了)...
GPU: 执行完命令 ← GPU 把旗子立起来
CPU: (旗子立了,醒来继续)
vkResetFences(fence) ← 把旗子放倒,下次再用
- 信号量(Semaphore):控制GPU端资源访问,保证呈现顺序,主要用于GPU等待GPU内部完成某些工作的情况,比如图形队列和呈现队列之间的同步。
vkQueueSubmit(graphicsQueue,
waitSemaphores = {},
signalSemaphores = {semaphore}) ← 图形队列:完成后发信号
vkQueueSubmit(presentQueue,
waitSemaphores = {semaphore}, ← 呈现队列:收到信号才开始
signalSemaphores = {})
- 管线屏障(Pipeline Barrier):控制GPU队列内的资源访问,做图像布局转换,主要用于GPU等待GPU内部完成某些工作的情况,例如在同一条命令缓冲中,前一个操作完成后才能进行下一个操作。
[操作1] 用布局 A 渲染到图像
↓
[vkCmdPipelineBarrier] ← 转换点:A → B
↓
[操作2] 用布局 B 采样这个图像
简单来说:
栅栏:GPU,你把这批命令执行完之后,给我(CPU)插一面旗子。我会在某个时刻过来看这面旗子立起来没有,立起来了我才继续往下走。
信号量:GPU,你把队列A的这批命令执行完之后,给队列B发一个信号。队列B收到信号之前,不许开始干活。
管线屏障:在我这条屏障指令之前提交的操作全部完成后,把这个图像从布局 A 转换到布局 B,然后后续操作才能开始。
对于栅栏与信号量:
VkSemaphoreCreateInfo semaphoreInfo = {
.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO
};
VkFenceCreateInfo fenceInfo = {
.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO,
// 创建时就让栅栏处于已信号状态,这样第一次提交命令时就不需要等待了。
.flags = VK_FENCE_CREATE_SIGNALED_BIT
};
std::vector<VkSemaphore> presentSemaphores(MAX_FRAMES_IN_FLIGHT);
std::vector<VkFence> inFlightFences(MAX_FRAMES_IN_FLIGHT);
std::vector<VkSemaphore> renderSemaphores;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
chk(vkCreateSemaphore(logicalDevice, &semaphoreInfo, nullptr, &presentSemaphores[i]));
chk(vkCreateFence(logicalDevice, &fenceInfo, nullptr, &inFlightFences[i]));
}
renderSemaphores.resize(swapchainImageCount);
for (size_t i = 0; i < swapchainImageCount; i++) {
chk(vkCreateSemaphore(logicalDevice, &semaphoreInfo, nullptr, &renderSemaphores[i]));
}
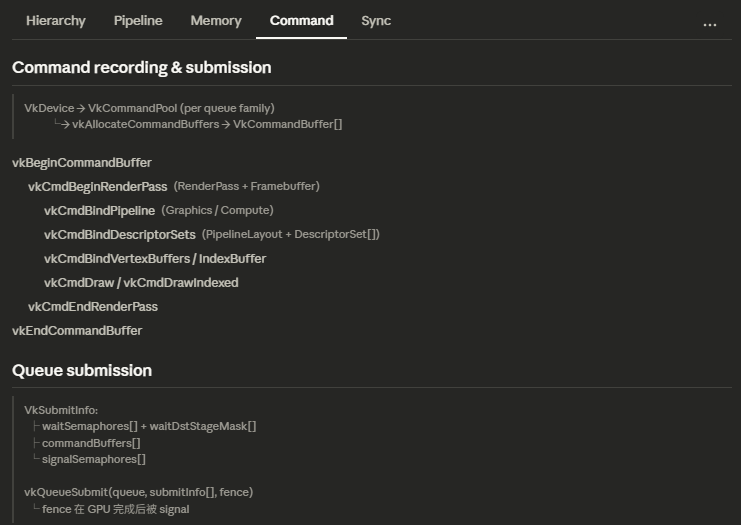
命令缓冲区¶
Vulkan需要先把命令记录到命令缓冲区,提交到队列后才能执行命令。
这么做的目的是让驱动能优化命令的执行方式,比如把多个绘制命令合并成一个批次,或者重新排序命令以提高性能。
此外,我们还可以多线程录制命令缓冲区,充分利用多核CPU的性能。
我们需要从命令池(Command Pool)中分配命令缓冲区:
VkCommandPoolCreateInfo poolInfo = {
.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO,
.queueFamilyIndex = graphicsQueueFamilyIndex,
// 允许命令缓冲区被重置,这样我们就不需要每次都销毁和重新创建命令缓冲区了。
.flags = VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT
};
chk(vkCreateCommandPool(logicalDevice, &poolInfo, nullptr, &commandPool));
VkCommandBufferAllocateInfo allocInfo = {
.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO,
.commandPool = commandPool,
.commandBufferCount = MAX_FRAMES_IN_FLIGHT
};
chk(vkAllocateCommandBuffers(logicalDevice, &allocInfo, commandBuffers.data()));
纹理加载¶
纹理在Vulkan中也是一种图像资源。图像资源本质上就是一块存储数据的内存。与缓冲区不同的是,图像资源还包含了布局和访问权限等信息,因此图像的上传比缓冲区更复杂。
KTX格式是一种专门为GPU纹理设计的文件格式,支持多种压缩格式和MIP级别,可以直接上传到GPU而无需转换。可以使用PVRTexTool创建KTX文件。
for(auto i=0;i<textures.size();i++>){
ktxTexture* ktxTexture = nullptr;
std::string filename = "assets/textures"+std::to_string(i)+".ktx";
// KTX_TEXTURE_CREATE_LOAD_IMAGE_DATA_BIT表示在创建纹理时直接加载图像数据,这样我们就不需要手动读取文件并上传数据了。
ktxTextureCreateFromNamedFile(filename.c_str(), KTX_TEXTURE_CREATE_LOAD_IMAGE_DATA_BIT, &ktxTexture);
}
加载好图像后,创建图像资源:
VkImageCreateInfo imageInfo = {
.sType = VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO,
.imageType = VK_IMAGE_TYPE_2D,
.format = ktxTexture_GetVkFormat(ktxTexture),
.extent{.width = ktxTexture->baseWidth, .height = ktxTexture->baseHeight, .depth = 1},
.mipLevels = ktxTexture->numLevels,
.arrayLayers = 1,
// 多采样图像需要更多的内存和带宽,但可以提供更好的抗锯齿效果。对于纹理图像来说,通常不需要多采样,所以设置为1。
.samples = VK_SAMPLE_COUNT_1_BIT,
// 让图像以GPU最优的方式进行布局和内存访问
.tiling = VK_IMAGE_TILING_OPTIMAL,
// 纹理图像需要作为着色器资源被采样,所以使用SAMPLED_BIT
.usage = VK_IMAGE_USAGE_SAMPLED_BIT |
// TRANSFER_DST_BIT表示我们要传数据进去
VK_IMAGE_USAGE_TRANSFER_DST_BIT,
// 不关心图像的初始内容,允许Vulkan以最优的方式处理图像内存
.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED,
};
VmaAllocationCreateInfo texImageAllocInfo = {
.usage = VMA_MEMORY_USAGE_AUTO,
};
chk(vmaCreateImage(allocator, &imageInfo, &texImageAllocInfo, &texture.image, &texture.allocation, nullptr));
创建视图以访问图像:
VkImageViewCreateInfo imageViewInfo = {
.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO,
.image = texture.image,
.viewType = VK_IMAGE_VIEW_TYPE_2D,
.format = imageInfo.format,
// 指定视图能访问图像的哪些部分。
// 例如,多Mip图像可以创建不同视图,每个视图访问不同的Mip级别。
.subresourceRange{
.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT,
.levelCount = ktxTexture->numLevels,
.layerCount = 1
},
};
chk(vkCreateImageView(logicalDevice, &imageViewInfo, nullptr, &texture.imageView));
VkBuffer imgSrcBuffer{};
VmaAllocation imgSrcBufferAlloc{};
VkBufferCreateInfo imgSrcBufferInfo = {
.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO,
.size = (uint32_t)ktxTexture->dataSize,
// TRANSFER_SRC_BIT表示这个缓冲区只会作为 vkCmdCopyBufferToImage 的数据来源,不会用来渲染或着色器读取。
.usage = VK_BUFFER_USAGE_TRANSFER_SRC_BIT,
};
VmaAllocationCreateInfo imgSrcBufferAllocInfo = {
.usage = VMA_MEMORY_USAGE_AUTO,
// HOST_VISIBLE_BIT表示这个缓冲区的内存可以被CPU访问,这样我们就可以直接把图像数据写入这个缓冲区了。
.flags = VMA_ALLOCATION_CREATE_HOST_ACCESS_SEQUENTIAL_WRITE_BIT |
// 让VMA分配完就把内存映射到CPU地址空间,这样我们就不需要额外的映射步骤了。
VMA_ALLOCATION_CREATE_MAPPED_BIT
};
chk(vmaCreateBuffer(allocator, &imgSrcBufferInfo, &imgSrcBufferAllocInfo, &imgSrcBuffer, &imgSrcBufferAlloc, nullptr));
void* imgSrcBufferPtr = nullptr;
// 这里其实不需要调用vmaMapMemory了,因为我们在分配缓冲区时已经使用了VMA_ALLOCATION_CREATE_MAPPED_BIT标志,VMA会自动将内存映射到CPU地址空间,并通过VmaAllocationInfo::pMappedData指针提供访问。但是为了代码的清晰和一致性,我们还是调用一下vmaMapMemory来获取映射指针。
chk(vmaMapMemory(allocator, imgSrcBufferAlloc, &imgSrcBufferPtr));
// 将KTX纹理数据复制到暂存缓冲区
memcpy(imgSrcBufferPtr, ktxTexture->pData, (size_t)ktxTexture->dataSize);
随后,用命令缓冲区把数据从缓冲区复制到图像:
VkFenceCreateInfo fenceInfo = {
.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO,
};
VkFence fenceOneTime;
chk(vkCreateFence(logicalDevice, &fenceInfo, nullptr, &fenceOneTime));
VkCommandBuffer cbOneTime;
VkCommandBufferAllocateInfo allocInfo = {
.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO,
.commandPool = commandPool,
.commandBufferCount = 1
};
chk(vkAllocateCommandBuffers(logicalDevice, &allocInfo, &cbOneTime));
创建栅栏和命令缓冲区的开销可以忽略不计。
随后,开始录制命令缓冲区。先转换图像布局,然后复制数据,最后再转换回着色器可访问的布局。
流程:布局转换(UNDEFINED → TRANSFER_DST_OPTIMAL)→ 按Mip级别复制数据 → 布局转换(TRANSFER_DST_OPTIMAL → SHADER_READ_ONLY_OPTIMAL)→ 提交命令 → 等待完成
为什么要布局转换?
图像资源在Vulkan中有不同的布局,表示图像当前的使用状态。不同的操作需要图像处于特定的布局才能正确执行。 复制数据到图像需要图像处于TRANSFER_DST_OPTIMAL布局,而着色器读取图像需要图像处于SHADER_READ_ONLY_OPTIMAL布局。
VkCommandBufferBeginInfo beginInfo = {
.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO,
// ONE_TIME_SUBMIT_BIT表示这个命令缓冲区只会被提交一次,这样驱动可以进行一些优化。
.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT
};
chk(vkBeginCommandBuffer(cbOneTime, &beginInfo));
// 图像布局转换:UNDEFINED → TRANSFER_DST_OPTIMAL
VkImageMemoryBarrier2 barrierToTransfer = {
.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER_2,
.srcStageMask = VK_PIPELINE_STAGE_2_NONE,
.srcAccessMask = VK_ACCESS_2_NONE,
.dstStageMask = VK_PIPELINE_STAGE_2_TRANSFER_BIT,
.dstAccessMask = VK_ACCESS_2_TRANSFER_WRITE_BIT,
.oldLayout = VK_IMAGE_LAYOUT_UNDEFINED,
.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL,
.image = texture.image,
.subresourceRange{
.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT,
.levelCount = ktxTexture->numLevels,
.layerCount = 1
},
};
// 使用vkCmdPipelineBarrier2进行图像布局转换,确保在复制数据之前,图像已经处于TRANSFER_DST_OPTIMAL布局,并且GPU知道我们将要写入这个图像。
VkDependencyInfo depInfoToTransfer = {
.sType = VK_STRUCTURE_TYPE_DEPENDENCY_INFO,
.imageMemoryBarrierCount = 1,
.pImageMemoryBarriers = &barrierToTransfer
};
vkCmdPipelineBarrier2(cbOneTime, &depInfoToTransfer);
// 从缓冲区复制数据到图像
std::vector<VkBufferImageCopy> copyRegions;
// KTX纹理可能包含多个MIP级别,我们需要为每个MIP级别设置一个复制区域。
for (uint32_t level = 0; level < ktxTexture->numLevels; level++) {
ktx_size_t mipOffset{0};
KTX_error_code ret = ktxTexture_GetImageOffset(ktxTexture, level, 0, 0, &mipOffset);
copyRegions.push_back({
.bufferOffset = mipOffset,
.imageSubresource = {
.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT,
.mipLevel = (uint32_t)level,
.baseArrayLayer = 0,
.layerCount = 1
},
// 纹理的每个MIP级别的尺寸是原始尺寸的1/2,依次类推
.imageExtent = {
ktxTexture->baseWidth >> level,
ktxTexture->baseHeight >> level,
1
}
});
}
vkCmdCopyBufferToImage(cbOneTime, imgSrcBuffer, texture.image, VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, static_cast<uint32_t>(copyRegions.size()), copyRegions.data());
VkImageMemoryBarrier2 barrierToShaderRead = {
.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER_2,
.srcStageMask = VK_PIPELINE_STAGE_2_TRANSFER_BIT,
.srcAccessMask = VK_ACCESS_2_TRANSFER_WRITE_BIT,
.dstStageMask = VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT,
.dstAccessMask = VK_ACCESS_SHADER_READ_BIT,
.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL,
.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL,
.image = texture.image,
.subresourceRange{
.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT,
.levelCount = ktxTexture->numLevels,
.layerCount = 1
},
};
depInfoToTransfer.pImageMemoryBarriers = &barrierToShaderRead;
vkCmdPipelineBarrier2(cbOneTime, &depInfoToTransfer);
chk(vkEndCommandBuffer(cbOneTime));
VkSubmitInfo oneTimeSubmitInfo = {
.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO,
.commandBufferCount = 1,
.pCommandBuffers = &cbOneTime
};
chk(vkQueueSubmit(graphicsQueue, 1, &oneTimeSubmitInfo, fenceOneTime));
// 等待命令执行完成
chk(vkWaitForFences(logicalDevice, 1, &fenceOneTime, VK_TRUE, UINT64_MAX));
完成纹理的布局转换和数据传输后,需要定义纹理采样器。
纹理采样器(Sampler)定义了纹理在着色器中被采样时的行为,例如过滤模式、地址模式等。
VkSamplerCreateInfo samplerInfo = {
.sType = VK_STRUCTURE_TYPE_SAMPLER_CREATE_INFO,
// 线性过滤表示在采样时会对相邻的像素进行插值,提供更平滑的结果。对于大多数纹理来说,线性过滤是更好的选择。
.magFilter = VK_FILTER_LINEAR,
.minFilter = VK_FILTER_LINEAR,
.mipmapMode = VK_SAMPLER_MIPMAP_MODE_LINEAR,
.anisotropyEnable = VK_TRUE,
.maxAnisotropy = 8.0f,
.maxLod = static_cast<float>(ktxTexture->numLevels),
};
chk(vkCreateSampler(logicalDevice, &samplerInfo, nullptr, &texture.sampler));
纹理资源需要使用描述符来绑定到着色器中。描述符是Vulkan中用于连接着色器资源和实际GPU资源的机制。描述符集(Descriptor Set)是描述符的集合,描述符池(Descriptor Pool)是用于分配描述符集的对象。
这里我们清空加载的纹理数据,并保存描述符信息
std::vector<VkDescriptorImageInfo> textureDescriptors;
ktxTexture_Destroy(ktxTexture);
for (auto& texture : textures) {
// 保存描述符信息
textureDescriptors.push_back({
.sampler = texture.sampler,
.imageView = texture.imageView,
.imageLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL
});
}